
| Version 27 (modified by , 16 years ago) ( diff ) |
|---|
この文書はArchtectural Overviewの9 Identificationの翻訳である。内容の正確性については保証しないので,正確な内容については原文を参照すること
9 識別情報
9 Identification TOC
9.1 EHRの識別情報
9.1 Identification of the EHR
openEHRシステムでは、EHRはそれぞれにEHR idとして知られ、各EHRを示すルートEHRオブジェクトでもある固有の識別子を持つ。EHR IDは信頼できるOIDやGUIDを作成するような全体で固有の「強い」識別子である。一つのシステム内に同じ対象を示す二つのEHRがあってはならない。もし、そうでない場合には、EHRシステムは対象となるEHRの存在を発見できず、対象に与えられたデモグラフィック属性を適合することもできないということになる.
In an openEHR system, each EHR has a unique identifier, known as the EHR id, found in the root EHR object of each EHR. EHR ids should be "strong" globally unique identifiers such as reliably created Oids or Guids. No single system should contain two EHRs for the same subject. If this is not the case, it means that the EHR system has failed to detect the existence of an EHR for a subject, or failed to match provided demographic attributes to the subject.
分散環境では,対象(例えば患者)に付与されたEHR IDは変化するものであり,環境の統合レベルにも依存する。統合されていないかあるいは、散発的に接続されるような環境では、同じ患者について各施設に分かれてEHRが存在し、各施設に固有のEHR IDであり、一方で同じ対象を示すIDをもつことになるだろう。ある一つの場所に存在する患者EHR部分的コピーが他の医療機関から要求された場合に、その場所のEHRと受け取ったアイテムを結合されることになる。そのような状況で永続的なCOMPOSITIONを結合させる場合には人間の介入を必要とすることもある。分散環境において複数のEHR IDが患者ごとに割り振られているということは,統合的な結合性や識別サービスがないということの証明でもある。
In a distributed environment, the correspondence of EHR ids to subjects (i.e. patients) is variable, and depends on the level of integration of the environment. In non-integrated or sporadically connected environments, the same patient is likely to have a separate EHR at each institution, each with its own unique EHR id, but the same subject id. If copies of parts of the patient EHR at one location is requested by another provider, the received items will be merged into the local EHR for that patient. Merges of persistent Compositions in such circumstances are likely to require human intervention. Multiple EHR ids per patient in a distributed context are evidence of a lack of systematic connectivity or identification service.
完全に統合された分散環境においては,複数の場所にローカルのEHRを持つが,それぞれが同じEHR IDを持つことになる。患者が新しい場所に現れると,その環境の識別サービスに対して,この患者のEHRが既にどこ何あるのではないかということを決定するための要求が行われるであろう。もし,存在するのであれば既存のEHRの全体/部分的なクローンが作られるか,新しく何も情報がないEHRが作成されるが,すべての場合においてEHR IDは同じ患者であれば他の場所で使われたものと同じものとなるだろう。
In a fully integrated distributed environment, the typical patient will still have local EHRs in multiple locations, but each carrying the same EHR id. When a patient presents in a new location, a request to the environment's identification service could be made to determine if there is already an EHR for this patient. If there is, a clone of all or part of the existing EHR could be made, or a new empty EHR could be created, but in all cases, the EHR id would be the same as that used in other locations for the same patient.
上記のロジックでは,openEHRのEHRがどの場所にあるのかだけを保持していることに注意しなくてはならない。
Note that the above logic only holds where the EHR in each location is an openEHR EHR.
9.2 EHR内部のアイテムの識別情報
9.2 Identification of Items within the EHR
9.2.1 汎用スキーム
9.2.1 General Scheme
EHRの識別がopenEHRでは完全に定義できるものではないのとはことなり,EHRに伴うアイテムの識別は完全に定義されている。ここで記述されたスキーマでは,2種類の「識別子(identifier)」が必要とされる。識別子そのものと,参照あるいはロケータである。識別子はオブジェクトに付けられた固有の(ある状況の範囲で)記号や番号を持ち,通常はオブジェクトの内部に記載されているのに対して,参照は問い合わせにおける識別子を含むオブジェクトを参照するために外部オブジェクトによる識別子が用いられている。この区別はリレーショナルデータベースシステムのプライマリーキーと外部キーの関係と同じようなものである。
While identification of EHRs is not completely definable by openEHR, the identification of items with an EHR is fully defined. The scheme described here requires two kinds of "identifier": identifiers proper and references, or locators. An identifier is a unique (within some context) symbol or number given to an object, and usually written into the object, whereas a reference is the use of an identifier by an exterior object, to refer to the object containing the identifier in question. This distinction is the same as that between primary and foreign keys in a relational database system.
openEHRのRM(参照モデル)では,識別子と参照はsupport.identificationパッケージにあるクラスの2つのグループで実装されている。さまざまな種類の識別子がOBJECT_IDから派生したクラスで定義されており,一方で参照はOBJECT_REFを継承したクラスで定義されている。図28にその違いを示す。ここには,OBJECT_ID(OBJECT_IDは抽象型であるため,実際の型は他のXXX_IDクラスとなる)と参照としての様々なOBJECT_REFクラスが示されている。
{kind=link}
In the openEHR RM, identifiers and references are implemented with two groups of classes defined in the support.identification package. Identifiers of various kinds are defined by descendant classes of OBJECT_ID, while references are defined by the classes inheriting from OBJECT_REF. The distinction is illustrated in FIGURE 28. Here we see two container objects with OBJECT_IDs (since OBJECT_ID is an abstract type, the actual type will be another XXX_ID class), and various OBJECT_REFs as references.

9.2.2 識別情報のレベル
9.2.2 Levels of Identification
外部からデータアイテムの位置を示すことができるように,識別情報はopenEHRでは以下のように3段階でサポートされている。
In order to make data items locatable from the outside, identification is supported at 3 levels in openEHR, as follows:
- バージョンコンテナ: VERSIONED_OBJECT(Coomon IM)は一意的に識別される
- 最上位コンテンツ構造: COMPOSITION,EHR_STATUS,PARTYなどのコンテンツ構造はそれぞれが保持しているVERSIONED_OBJECTと同じく保持していてコンテナ内にあるVERSION識別子との関連により一意に識別される
- 内部ノード: 最上位構造内のノードはパスを使って識別される。
- version containers: VERSIONED_OBJECTs (Common IM) are identified uniquely;
- top-level content structures: content structures such as COMPOSITION, EHR_STATUS, EHR_ACCESS, PARTY etc. are uniquely identified by the association of the identifier of their containing VERSIONED_OBJECT and the identifier of their containing VERSION within the container;
- internal nodes: nodes within top-level structures are identified using paths.
3種類の識別情報は個々に用いられている。バージョンコンテナのために,固有の識別子("uids")が用いられている。ほとんどの場合,UIDクラスのサブタイプのインスタンスを持つHIER_OBJECT_ID型が用いられるであろう。UIDクラスは,たとえばISOのOIDか,もしくはIETFのUUID(http://www.ietf.org/rfc/rfc4122.txt を参照。GUIDとしても知られている)である。中央での割り付けが不要であることや,その場で生成することができることから,一般的にはUUIDのほうが望ましい。バージョンコンテナは識別子を持つOBJECT_REFにより参照される。
Three kinds of identification are used respectively. For version containers, meaningless unique identifiers ("uids") are used. In most cases, the type HIER_OBJECT_ID will be used, which contains an instance of a subtype of the UID class, i.e. either an ISO OID or a IETF UUID (see http://www.ietf.org/rfc/rfc4122.txt; also known as a GUID). In general UUIDs are favoured since they require no central assignment and can be generated on the spot. A versioned container can be then referenced with an OBJECT_REF containing its identifier.
最上位構造のバージョンは複製や結合とそれによって起きる修正がなされるような分散環境においても動作が保証される方法で識別される。最上位構造のバージョンを完全に識別する情報は,VERSIONED_OBJECTを含むUIDと,VERSIONが持つversion_tree_idとcreating_system_idの2つの属性の組み合わせにより全体で一意となる。version_tree_idは"1"あるいはそのブランチを示す"1.2.1"のような1つあるいは3つの部分に分かれた数字である。creating_system_id属性にはコンテンツが最初に作られたシステムのために固有の識別子が付与される。これはGUIDや,OID,あるいはリバースインターネット識別子となるだろう。標準的なバージョン識別子の組み合わせは以下のようなものである
Versions of top-level structures are identified in a way that is guaranteed to work even in distributed environments where copying, merging and subsequent modification occur. The full identification of a version of a top-level structure is the globally unique tuple consisting of the uid of the owning VERSIONED_OBJECT, and the two VERSION attributes version_tree_id and creating_system_id. The version_tree_id is a 1 or 3-part number string, such as "1" or for a branch, "1.2.1". The creating_system_id attribute carries a unique identifier for the system where the content was first created; this may be a GUID, Oid or reverse internet identifier. A typical version identification tuple is as follows:
F7C5C7B7-75DB-4b39-9A1E-C0BA9BFDBDEC -- VERSIONED_COMPOSITIONのID
au.gov.health.rdh.ehr1 -- 作成されたシステムのID
2 -- 現行バージョン
F7C5C7B7-75DB-4b39-9A1E-C0BA9BFDBDEC -- id of VERSIONED_COMPOSITION
au.gov.health.rdh.ehr1 -- id of creating system
2 -- current version
この3つ要素がある組み合わせは,「バージョンロケータ」としてしられており,support.identificationパッケージのOBJECT_VERSION_IDクラスで定義されている。VERSIONはOBJECT_VERSION_IDでバージョンのコピーを付与された通常のOBJECT_REFを使って参照することができる。openEHRのバージョン識別方法は,共通情報モデル(Common IM)のchange_controlパッケージ部分に詳細が記述されている。
This 3-part tuple is known as a "Version locator" and is defined by the class OBJECT_VERSION_ID in the support.identification package. A VERSION can be referred to using a normal OBJECT_REF that contains a copy of the version's OBJECT_VERSION_ID. The openEHR version identification scheme is described in detail in the change_control package section of the Common IM.
識別情報の最後のコンポーネントはパスであり,バージョンロケータで識別される最上位構造の下のノードとして参照される。openEHRでのパスはXpathスタイルの文法に従っており,もっともよくある場合においてパスを短縮するために,少し略語が用いられている。パスは以下で詳細に記述されている。
The last component of identification is the path, used to refer to an interior node of a top-level structure identified by its Version locator. Paths in openEHR follow an Xpath style syntax, with slight abbreviations to shorten paths in the most common cases. Paths are described in detail below.
最上位構造から,下位のデータノードを参照するためにはバージョンロケータとパスの組み合わせが必要である。これは,共通情報モデル(Common IM)のchange_controlパッケージセクションにあるLOCATABLE_REFクラスで形式化されている。URI(Universal Resource Identifier)形式も利用することができ,DV_EHR_URI(Data types IM)のデータ型で定義されている。このデータ型を用いると,どこからでも下位のデータノードを参照することができるように利用される"ehr://"というスキーマ空間を使った一つの文字表現を利用できる(この表現は問い合わせを表現するためにも利用できる。下記参照)。LOCATABLE_REFはすべて,DV_EHR_URIに変換することができるが,すべてのDV_EHR_URIがLOCATABLE_REFに変換できるというわけではない。
To refer to an interior data node from outside a top-level structure, a combination of a Version locator and a path is required. This is formalised in the LOCATABLE_REF class in the change_control package section of the Common IM. A Universal Resource Identifier (URI) form can also be used, defined by the data type DV_EHR_URI (Data types IM). This type provides a single string expression in the scheme-space "ehr://" which can be used to refer to an interior data node from anywhere (it can also be used to represent queries; see below). Any LOCATABLE_REF can be converted to a DV_EHR_URI, although not all DV_EHR_URIs are LOCATABLE_REFs.
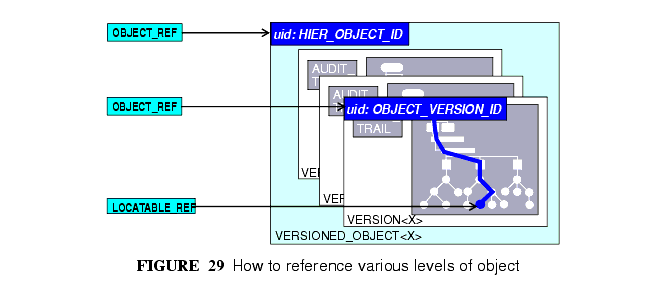
図29はどのようなOBJECT_ID型とOBJECT_REF型がオブジェクトを識別し,外部から参照するために用いられているか,それぞれについて要約している。
{kind=link}
FIGURE 29 summarises how various types of OBJECT_ID and OBJECT_REF are used to identify objects, and to reference them from the outside, respectively.

Attachments (2)
- identificationa.gif (21.5 KB ) - added by 16 years ago.
- identification2.gif (36.2 KB ) - added by 16 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip