
| Version 19 (modified by , 17 years ago) ( diff ) |
|---|
4 設計原則
TOC 4 Design Principles
openEHRの情報やサービス,そのドメインでの知識をモデル化するアプローチは以下に記述するような多くの設計原則を元にしている。これらの原則を適用することで,openEHRアーキテクチャモデルを分離することができ,高レベルのコンポーネント化ができるようになった。これにより保守性や拡張性,柔軟な配備が可能となった。
The openEHR approach to modelling information, services and domain knowledge is based on a number of design principles, described below. The application of these principles lead to a separation of the models of the openEHR architecture, and consequently, a high level of componentisation. This leads to better maintainability, extensibility, and flexible deployment.
4.1 オントロジー的分離
4.1 Ontological Separation
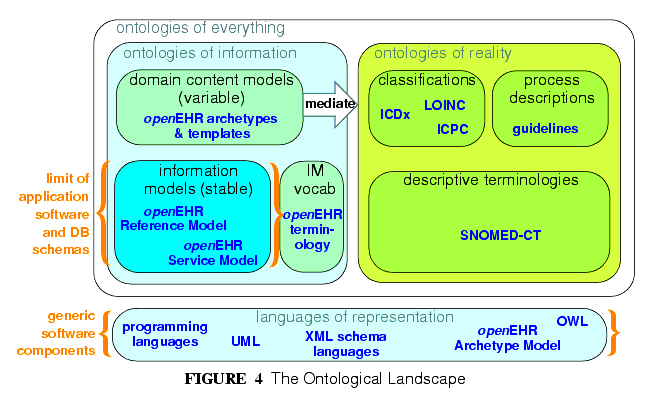
どのモデル化する体系でももっとも基本的な種類の特徴はオントロジーによる(例えば,現実世界の抽象化レベルなど)ものである。すべてのモデルはある種の意味論的内容を持つが,その意味するところは同じカテゴリーであっても同じではない。例えば,SNOMED-CTFootNote(See http://www.snomed.org)用語体系は細菌感染の種類を体のどこの部位か,症候の種類はどうかで記述している。情報モデルは論理型の「量」を指定する可能性がある。内容モデルは内科医による出生後の診察で得られた情報のモデルを定義することができるかもしれない。これらの「情報」の型は質的に異なり,すべての生態系モデルとは分離して開発し,維持される必要がある。図4はこれらの差異を図示し,どの部分がソフトウェアやデータベースとに直接構築されるかを示している。
{kind=link}

The most basic kind of distinction in any system of models is ontological, i.e. in the levels of abstraction of description of the real world. All models carry some kind of semantic content, but not all semantics are the same, or even of the same category. For example, some part of the SNOMED-CTFootNote(See http://www.snomed.org) terminology describes types of bacterial infection, sites in the body, and symptoms. An information model might specify a logical type Quantity. A content model might define the model of information collected in an ante-natal examination by a physician. These types of "information" are qualitatively different, and need to be developed and maintained separately within the overall model eco-system. FIGURE 4 illustrates these distinctions, and indicates what parts are built directly into software and databases.
この図では,情報のオントロジーを第一に分類して示している。たとえば,情報の内容モデルと「現実のオントロジー」であり,表現と現象の分類ということでもある。これらの二つのカテゴリーは作者や表現,その目的の種類が完全に異なるために分離しなければならない。医療情報学では,用語体系や分類の開発が進められたためにこの分離は既に大きく存在している。
This figure shows a primary separation between "ontologies of information" i.e. models of information content, and "ontologies of reality" i.e. descriptions and classifications of real phenomena. These two categories have to be separated because the type of authors, the representation and the purposes are completely different. In health informatics, this separation already exists by and laubuntu x60srge, due to the development of terminologies and classifications.
情報側からの第2のオントロジー的分離は情報モデルとドメイン内容モデルの間にある。前のカテゴリー(情報モデル)はドメインと常に直交する(例えばコード化された用語のような基本的データ型や、IDやリストのようなデータ構造)セマンティクスに対応しているが、後者(ドメイン内容モデル)は実世界で起こる実際の現象(例えば、微生物による感染)というよりもむしろ、様々なドメインレベルの内容を表現するもの(情報構造についての表現、例えば「微生物学的検査」の情報構造)に対応する。子の分離は一般にはあまり理解されていないが、歴史的には多くのドメインレベルセマンティクスがソフトウェアやデータベースに組み込まれており、比較的に維持できないようなシステムにも導入されている。
A secondary ontological separation within the information side is shown between information models and domain content models. The former category corresponds to semantics that are invariant across the domain (e.g. basic data types like coded terms, data structures like lists, identifiers), while the latter corresponds to variable domain level content descriptions - descriptions of information structures such as "microbiology result" rather than descriptions of actual phenomena in the real world (such as infection by a microbe). This separation is not generally well understood, and historically, a great deal of domain-level semantics has been hard-wired into the software and databases, leading to relatively unmaintainable systems.
情報モデル、ドメイン内容モデル、用語体系の3つのカテゴリーを明確に分離することにより、openEHRアーキテクチャは明確で、限定されたスコープと、整理されたインターフェースをそれぞれに持つことができている。これにより、お互いの依存関係を制限することができ、維持しやすく、より適合性の高いシステムとなっている。
By clearly separating the three categories - information models, domain content models, and terminologies - the openEHR architecture enables each to have a well-defined, limited scope and clear interfaces. This limits the dependence of each on the other, leading to more maintainable and adaptable systems.
2段階モデリングとアーキタイプ
Two-level Modelling and Archetypes
openEHRの基礎となっている重要なパラダイムの一つは、「2段階」モデリングとして知られているFootNote(Beale T. Archetypes: Constraint-based Domain Models for Future-proof Information Systems. OOPSLA 2002 workshop on behavioural semantics. Available at http://www.deepthought.com.au.)。2段階アプローチでは、安定した参照情報モデルが第1段階のモデリングであり、さらに臨床内容をアーキタイプ形式やテンプレートで定義して構成することが第2段階のモデリングである。第1段階(参照モデル)をソフトウェアに実装するだけで、配備されるシステムと様々な内用で定義されるデータの依存関係を有意に減らすことができる。モデル全般の別の部分でさえも極めて安定した言語やモデルにより表現することができる(図4の最下部)。結果として、システムは1段階のシステムよりもはるかに小さく、維持しやすいものとすることができる。将来に向けてアーキタイプとテンプレートを使って開発してくことで、システムはまた本質的に自己適応するものとなる。
One of the key paradigms on which openEHR is based is known as "two-level" modelling, described in [2]. Under the two-level approach, a stable reference information model constitutes the first level of modelling, while formal definitions of clinical content in the form of archetypes and templates constitute the second. Only the first level (the Reference Model) is implemented in software, significantly reducing the dependency of deployed systems and data on variable content definitions. The only other parts of the model universe implemented in software are highly stable languages/models of representation (shown at the bottom of FIGURE 4). As a consequence, systems have the possibility of being far smaller and more maintainable than single-level systems. They are also inherently self-adapting, since they are built to consume archetypes and templates as they are developed into the future.
アーキタイプとテンプレートはまた、用語体系や分類、コンピュータ化された臨床ガイドラインに対してセマンティクスを与えるものである。過去には他の方法で、システムの機能を固有のソフトウェアと用語体系の組み合わせだけで構築しようと試みられていた。この手法には欠点がある。用語体系はドメイン内容の定義を含まず、元実世界の事実(例えば、微生物の種類とそれが人体に与える影響)をむしろ定義するものであるからである
Archetypes and templates also act as a well-defined semantic gateway to terminologies, classifications and computerised clinical guidelines. The alternative in the past has been to try to make systems function solely with a combination of hard-wired software and terminology. This approach is flawed, since terminologies don't contain definitions of domain content (e.g. "microbiology result"), but rather facts about the real world (e.g. kinds of microbes and the effects of infection in humans).
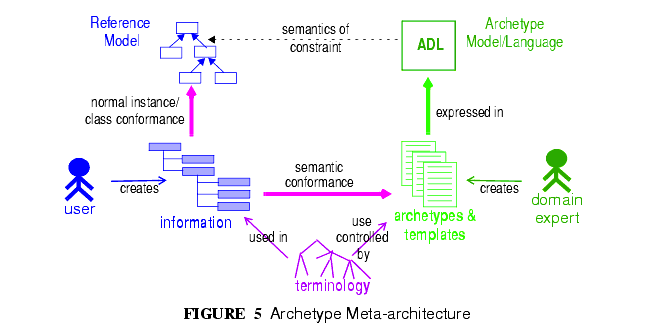
openEHRでアーキタイプを使っていくことで、図5のように情報とモデルの新しい関係を作り出すことができる。
{kind=link}
The use of archetyping in openEHR engenders new relationships between information and models, as shown in FIGURE 5.

この図では、通常の情報システム(図5一番左下)で知られているような「データ」は通常ではオブジェクトモデル(一番左上)に相当する。システムは
In this figure, "data" as we know it in normal information systems (shown on the bottom left) conforms in the usual way to an object model (top left). Systems engineered in the "classic" way (i.e. all domain semantics are encoded somewhere in the software or database) are limited to this kind of architecture. With the use of two-level modelling, runtime data now conform semantically to archetypes as well as concretely to the reference model. All archetypes are expressed in a generic Archetype Definition Language (ADL).
The details of how archetypes and templates work in openEHR are described in Archetypes and Templates on page 55. Consequences for Software Engineering
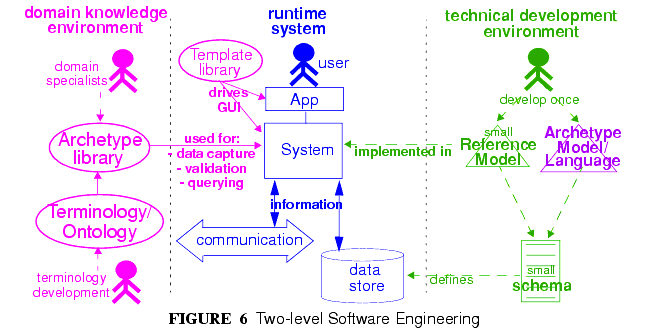
Two-level modelling significantly changes the dynamics of the systems development process. In the usual IT-intensive process, requirements are gathered via ad hoc discussions with users (typically via the well-known "use case" methodology), designs and models built from the requirements, implementation proceeds from the design, followed by testing and deployment and ultimately the maintenance part of the lifecycle. This is usually characterised by ongoing high costs of implementation change and/or a widening gap between system capabilities and the requirements at any moment. The approach also suffers from the fact that ad hoc conversations with systems users nearly always fails to reveal underlying content and workflow. Under the two-level paradigm, the core part of the system is based on the reference and archetype models (includes generic logic for storage, querying, caching etc.), both of which are extremely stable, while domain semantics are mostly delegated to domain specialists who work building archetypes (reusable), templates (local use) and terminology (general use). The process is illustrated in FIGURE 6. Within this process, IT developers concentrate on generic components such as data management and interoperability, while groups of domain experts work outside the software development process, generating definitions that are used by systems at runtime.
Clearly applications cannot always be totally generic (although many data capture and viewing applications are); decision support, administrative, scheduling and many other applications still require custom engineering. However, all such applications can now rely on an archetype- and template-driven computing platform. A key result of this approach is that archetypes now constitute a technology-independent, single-source expression of domain semantics, used to drive database schemas, software logic, GUI screen definitions, message schemas and all other technical expressions of the semantics. 4.2 Separation of Responsibilities
A second key design paradigm used in openEHR is that of separation of responsibilities within the computing environment. Complex domains are only tractable if the functionality is first partitioned into broad areas of interest, i.e. into a "system of systems" [6]. This principle has been understood in computer science for a long time under the rubrics "low coupling", "encapsulation" and "componentisation", and has resulted in highly successful frameworks and standards, including the OMG's CORBA specifications and the explosion of object-oriented languages, libraries and frameworks. Each area of functionality forms a focal point for a set of models formally describing that area, which, taken together usually correspond to a distinct information system or service.
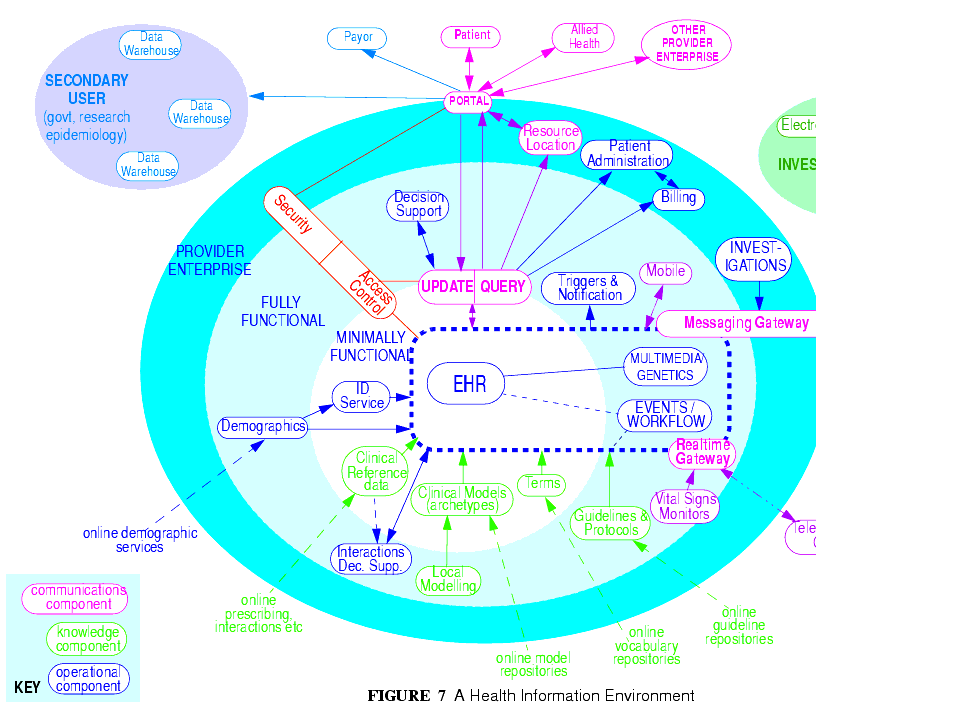
FIGURE 7 illustrates a notional health information environment containing numerous services, each denoted by a bubble. Typical connections are indicated by lines, and bubbles closer to the centre correspond to services closer to the core needs of clinical care delivery, such as the EHR, terminology, demographics/identification and medical reference data. Of the services shown on the diagram, openEHR currently provides specifications only for the more central ones, including EHR and Demographics.
Since there are standards available for some aspects of many services, such as terminology, image formats, messages, EHR Extracts, service-based interoperation, and numerous standards for details such as date/time formats and string encoding, the openEHR specifications often act as a mechanism to integrate existing standards. 4.3 Separation of Viewpoints
The third computing paradigm used in openEHR is a natural consequence of the separation of responsibilities, namely the separation of viewpoints. When responsibilities are divided up among distinct components, it becomes necessary to define a) the information that each processes, and b) how they will communicate. These two aspects of models constitute the two central "viewpoints" of the ISO RM/ODP model [4], marked in bold in the following:
- Enterprise: concerned with the business activities, i.e. purpose, scope and policies of the specified system.
- Information: concerned with the semantics of information that needs to be stored and processed in the system.
- Computational: concerned with the description of the system as a set of objects that interact at interfaces - enabling system distribution.
- Engineering: concerned with the mechanisms supporting system distribution.
- Technological: concerned with the detail of the components from which the distributed system is constructed.
The openEHR specifications accordingly include an information viewpoint - the openEHR Reference Model - and a computational viewpoint - the openEHR Service Model. The Engineering viewpoint corresponds to the Implementation Technology Specification (ITS) models of openEHR (see Implementation Technology Specifications on page 83), while the Technological viewpoint corresponds to the technologies and components used in an actual deployment. An important aspect of the division into viewpoints is that there is generally not a 1:1 relationship between model specifications in each viewpoint. For example, there might be a concept of "health mandate" (a CEN ENV13940 Continuity of Care concept) in the enterprise viewpoint. In the information viewpoint, this might have become a model containing many classes. In the computational viewpoint, the information structures defined in the information viewpoint are likely to recur in multiple services, and there may or may not be a "health mandate" service. The granularity of services defined in the computational viewpoint corresponds most strongly to divisions of function in an enterprise or region, while the granularity of components in the information view points corresponds to the granularity of mental concepts in the problem space, the latter almost always being more fine-grained.
Attachments (4)
- design_principles4.gif (64.8 KB ) - added by 17 years ago.
- design_principles3.gif (31.4 KB ) - added by 17 years ago.
- design_principles2.gif (45.8 KB ) - added by 17 years ago.
- design_principlesa.gif (151.5 KB ) - added by 17 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip