
| Version 6 (modified by , 16 years ago) ( diff ) |
|---|
この文書はArchtectural Overviewの12 Terminology in openEHR の翻訳である。正確性については保証しないので,適宜原文を参照すること
12 openEHRの用語体系
12 Terminology in openEHR TOC
12.1 概要
12.1 Overview
openEHRのアーキタイプは、医療及び関連データの意味を定義するための強力な方法を提供し、データをLOINC、ICDx、ICPC、SNOMED-CT等の認知された用語体系やヘルスケアで用いられるその他の多数の用語体系や語彙に接続し、"バインド"する。用語体系は、openEHRにおいて以下の方法で用いられる。
- リファレンス・モデルにおけるコード化された属性値は、"opneEHR"用語体系によって定義される。
- 各アーキタイプは、それぞれの内部用語体系を包含しており、各構成要素の意味を定義づける。
- 外部用語体系へのバインドをアーキタイプに含めることが可能であり、用語への直接のマッピングや、特定の値集合を返すクエリへのマッピングが許容される。
- 外部用語体系を用いるEHRクエリは、アーキタイプのバインドによってサポートされる。
以下のセクションでこれらの機構を記述する。
openEHR archetypes provide a powerful way to define the meaning of clinical and related data, and to connect, or "bind", data to recognised terminologies such as LOINC, ICDx, ICPC, SNOMED-CT and the many other terminologies and vocabularies used in healthcare. Terminology is used in openEHR in the following ways:
- The values of coded attributes in the reference model are defined by an "openEHR" terminology.
- Each archetype contains its own internal terminology, defining the meaning of each element.
- Bindings to external terminologies can be included in an archetype, allowing direct mappings to terms, or mappings to queries that return specific value sets.
- Querying the EHR using external terminologies is supported by archetype bindings.
The following sections describe these features.
12.2 参照モデルをサポートするための用語体系
12.2 Terminology to Support the Reference Model
openEHRは、それ自身の小さな用語体系とコード・セットを持っており、これらはレファレンス・モデルにおける多数の属性の値集合を提供するために用いられる。コード・セットは、よく知られた国際標準のコードのリストを表現するために用いられ、ここではたとえばISO 3166のカントリー・コード("au"、"cn"、"pl"等)のようにコード自体が意味のある値を持つ。6種のこのようなコード・セットが、リファレンス・モデルの各CODE_PHRASE型(用語コードを表すopenEHR型)において、さまざまな属性に用いられる。
openEHR has its own small terminology and code sets, which are used to provide the value sets of a number of attributes in the reference model. Code sets are used to express well-known internationally standardised lists of codes where the codes themselves have meaningful values e.g. the ISO 3166 country codes ("au", "cn", "pl" etc). Six such code sets are used by various attributes in the reference model, each of type CODE_PHRASE (the openEHR type used to represent a term code).
リファレンス・モデルにおけるPARTICIPATION.functionのような、他のコード化された属性のために、openEHR用語体系は、用語体系設計においてもっとオーソドックスなやり方をとっており、値集合を意味を持たないコードや指標(rubric)で定義する。これらの属性は常にDV_CODED_TEXT型であり、コード自体はdefining.code属性内に格納される。
For other coded attributes, such as PARTICIPATION.function in the reference model, the openEHR terminology takes the more orthodox route in terminology design, and defines value sets in groups using meaningless codes and rubrics. These attributes are always of type DV_CODED_TEXT; the code itself is contained within the defining_code attribute.
openEHR用語体系は、openEHR用語体型ドキュメントFootNote(1)中に記述されており、openEHR用語体系ページFootNote(2)にはコンピュータ処理向けの表現も利用可能となっている。
The openEHR terminology is described in the openEHR Terminology document1, with computable expressions available at the openEHR terminology page2.
12.3 アーキタイプ内部用語体系
12.3 Archetype Internal Terminology
アーキタイプは、それ自身のローカルな用語体系を保有している(アーキタイプの'オントロジー'セクションに見出せる)。内部的な用語集合の使用は、用語に構造(すなわちリレーション)が存在せず、シノニムが重要でない場合には適切である。従って、小規模な用語のフラット・リストに限定して使用される。アーキタイプに内蔵される用語の有用性は、上述のコンピュータ処理の効率性を別にして、以下の通りである。
- クエリをアーキタイプのみに基づいて行うことができ、ターミノロジー・サーバーの仲介を要さない。
- 用語の解釈は明確にセマティック(thematic)な文脈内で行われ(なぜならどのアーキタイプも特定のトピックに関するものであるから)、それゆえに格段に正確であると言える。
- アーキタイプで要求される用語の多くは、巨大な用語体系にも含まれていない。
- 用語体系を共有していない人でもアーキタイプに基づいてデータを共有できる。
Archetypes contain their own local terminology (found in the `ontology' section of an archetype). The use of internal term sets is appropriate when there is no structure to the terms (ie no relationships) and when synonyms are not important. Thus, the use is limited to small flat lists of terms. The advantages of the terms being internal to the archetype, apart from computational efficiency mentioned above, are:
- Queries can be based on archetypes alone and do not require interacting with a terminology server;
- Translation of the terms is made within an explicit thematic context (since every archetype is about a specific topic) and is therefore far more likely to be accurate;
- Many terms required in archetypes are not available even in very large terminologies;
- People can share data based on archetypes even if they do not share terminologies.
だが、自動処理の利点を最大限に享受するには、多くのアーキタイプが外部用語体系に接続する必要があることは明白である。これについては次のセクションに記述する。
It is clear, however, that many archetypes require a connection to external terminologies to provide the full benefits of automatic processing; this is described in the next section.
内部用語体系は、アーキタイプ構造の各ノードのセマンティックな定義である{code, text, description} の集合という形式をとる。これらの各用語は、"at"(archetype term)コード(たとえば[at0012])で定義される。アーキタイプ内でローカルに定義される各コードは、2つの目的のうちいずれかのために用いられる。
- アーキタイプのデータノードをセマンティックに識別する(すなわちデータの"名前") 、もしくは
- 枝葉属性の値集合を与える、のいずれか。
The internal terminology takes the form of a set of {code, text, description} semantic definitions for each node of the archetype structure. Each such term is identified by an "at" (archetype term) code, e.g. [at0012]. Each code defined locally in an archetype is used for one of two purposes:
- either to semantically identify the data nodes of the archetype (i.e. to "name" the data), or
- to provide value-sets for leaf attributes.
たとえば、"アプガー結果"FootNote(3) アーキタイプのローカル・コードは、"1分後事象"や"2分後事象"といった用語を含むであろう。これらのコードは、アーキタイプの'definition'パート内でレファレンス・モデルのノードと関連づけられている。アプガーの例では、2つのコード(すなわち [at0003] と [at0026]) は、図34に示すように、リファレンス・モデルの型であるEVENT (rm.data_structures.history パッケージ)にマッピングされるであろう。アーキタイプ・パスのベースとなるのは、このマッピングなのである。アーキタイプ・パスとは、単にリファレンス・モデルの属性名やノード・コードの代替パターンである。
For example, the local codes in an "Apgar result"3 archetype could contain terms for "1 minute event" and "2 minute event". These codes are associated with the reference model nodes within the `definition' part of the archetype. In the Apgar example, the two codes (say [at0003] and [at0026]) will be mapped to nodes of reference model type EVENT (rm.data_structures.history package), as shown in FIGURE 34. It is this mapping that is the basis for archetype paths: an archetype path is simply the alternating pattern of reference model attribute names and node codes.

ローカル・コードの2つ目の用途は、値としてである。図34で、コード [at0005] で識別されるELEMENTノードは、0、1または2という値の制約のあるORDINAL型を持っている。これらの各値は、コード [at0006]、[at0007] 及び [at0008] によって与えられる。アーキタイプ・オントロジーからこれらの用語が抽出される様子を図35に示す。
The second use of local codes is as values. In FIGURE 34, the ELEMENT node identified by code [at0005] has as its value constraint an ORDINAL type whose values can be 0, 1, or 2. Each of these values is coded by the codes [at0006], [at0007], and [at0008]. An extract of the archetype ontology showing these terms is shown in FIGURE 35.

12.4 外部用語体系のバインド
12.4 Binding to External Terminologies
外部用語体系コードのアーキタイプ・コードへのバインド
Binding External Terminology Codes to Archetype Codes
バインドの1種類目は、あるアーキタイプの範囲内で一つの内部コードを外部用語体系からの一つコードにマッピングする機能である。バインドは外部用語体系に基づいてグループ化され、アーキタイプ内のいかなる所与の内部コードも複数の用語体系のコードへのバインドが許される。通常、外部用語体系によって提供される範囲は不完全であり、マッピングは近似的なものになりがちであることから、最初にマッピングを生成する際には注意が必要である。図35で示した例では、2つのパスが、それぞれ1分後と2分後のアプガー・スコアに関するLOINCコードにバインドするものとして示されている。この例では、パス全体がバインドされており、[at0025] が第1のパスで発生した場合は [at0025] と [LNC205::9272-6] の間でのみマッピングを保持し、第2のパスで発生した場合は異なるLOINCコードにマッピングされることを意味している。このようにして、外部用語体系からのいわゆる"結合済み"コードは、openEHRアーキタイプ概念へとマッピングされるのである。
The first kind of binding is the ability within an archetype to map an internal code to a code from an external terminology. The bindings are grouped on the basis of external terminology, allowing any given internal code in an archetype to be bound to codes in multiple terminologies. Usually, coverage provided by external terminologies is incomplete, and the mappings may be approximate, so care must be taken in creating the mappings in the first place. In the example shown in FIGURE 35, two paths are shown respectively as being bound to LOINC codes for 1-minute and 2-minute Apgar total. In this example, the whole path is bound, meaning that the mapping only holds between [at0025] and [LNC205::9272-6] when [at0025] occurs in the first path; when it occurs in the second path, the mapping is to a different LOINC code. This is how so-called "pre-coordinated" codes from external terminologies can be mapped to an openEHR archetype concept.
バインドは、原子内部コードと外部コードの間でも行うことができる。このばあいは、アーキタイプ内で内部コードが使用される回数とは無関係にマッピングが常に保持されることを意味する。
Bindings can also be made between atomic internal codes and external codes, in which case the meaning is that the mapping always holds, no matter how many times the internal code is used within the archetype.
用語体系の値集合のアーキタイプへのバインド
Binding Terminology Value-sets to Archetypes
用語体系に関する重要な要求事項は、アーキタイプ内で定義される属性の値集合を特定することである。しばしば値集合はアーキタイプ内でローカルに定義されるが、これは用語が公開された用語体系中で利用可能ではないからであり、カプセル化の欠如のためにその場で定義することはどのような場合でも困難に過ぎるであろう。たとえば"ない"、"弱々しく泣く"、"強く泣く"といった用語は、アプガー結果FootNote(4)の"呼吸"属性の値として認知されている。アプガー/呼吸の文脈において、意味は明確であるけれども、SNOMED-CTのような用語体系内のこうした指標を伴う用語は明らかに結合済みである必要があろう。さらに重要なことは、SNOMED用語を"ない"に対してマッピングすることには、ほとんど実用上の価値がないと思われることである。なぜなら、 "ない"を含む項目に対するクエリなど、医療の文脈ではおよそ役に立たないからである。
An important requirement with respect to terminology is that of specifying value sets for attributes defined in archetypes. Sometimes value sets are defined locally within the archetype, because the terms are not available in published terminologies, and in any case may be too hard to define therein, due to the lack of encapsulation. The terms "no effort", "moderate effort" and "crying" for example are recognised values for the "breathing" attribute of an Apgar result4. In the context of Apgar / breathing, the meanings are clear; clearly however a term with this rubric within a terminology like SNOMED-CT would need to be pre-coordinated. More importantly, there seems to be little business value in mapping a SNOMED term for "no effort", since a query for items containing "no effort" is unlikely to be useful in a clinical context.
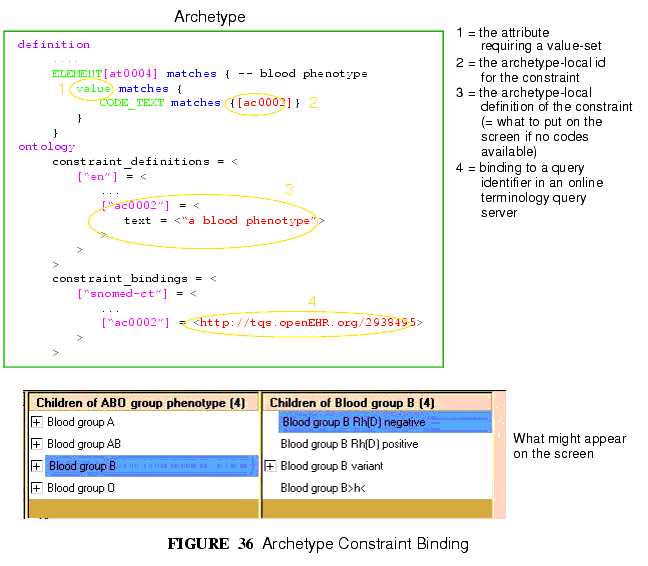
だが、他の多くの種類の属性では、用語体系は値についての適切なソースである。しばしばこのような属性は、疾病の種類や血液型といった現実世界の現象の種類を定義しており、"ない"とか"蒼白"といった現象の質的な面ではない。このような属性については、外部用語体系への異種の接続が求められる。このことは単一コードのバインドと同様の方法で達成される。ある内部コードは、この場合は"ac"コード("ac" = archetype constraint)として定義され、ひとつまたはそれ以上の外部用語体系へのクエリにバインドされ、その結果は用語体系からの(可能ならば構造化された)値の集合となる。属性値が"血液型"としてコード化される論理的なスキーマを図36に図示する。
For many other kinds of attributes however, terminologies are an appropriate source of values. Often such attributes define kinds of real world phenomena, such as kinds of disease and blood groups, rather than qualities of a phenomenon such as "no effort", or "blue". For these attributes a different kind of connection to external terminology is required. This is achieved in a similar way as for single code bindings: an internal code is defined, in this case an "ac" code ("ac" = archetype constraint), and this is bound to queries to one or more external terminologies, whose result would be a (possibly structured) value set from that terminology. The logical scheme is illustrated in FIGURE 36, where he attribute value to be coded is "blood group phenotype".

現時点では、このようなクエリに対する標準は存在しない。このことは、アーキタイプに対して直接影響しない。なぜなら、アーキタイプは単にクエリのための識別子を保持しているだけであり、クエリ自体は"ターミノロジー・クエリ・サーバー"内で定義されるからである。このクエリの結果は、図36の下方に示されるように、血液型のリストとなる。
Currently there is no standard for such queries. This does not affect archetypes directly, since they simply hold an identifier for a query; the query itself is defined within a "terminology query server". The result of this query is a list of blood group phenotypes, which might appear as shown at the bottom of FIGURE 36.
12.5 外部用語体系を用いたクエリ
12.5 Querying using External Terminologies
EHRデータへのクエリは、健康情報に関する用語体系の主要な用途として、しばしば引用される。アーキタイプで定義されたマッピングを用いれば、多数のアプローチが可能であるが、意図するクエリのセマンティクスが最初に理解される必要がある。患者記録での"腺癌(adenocarcinoma)"のクエリを考察してみよう。SNOMED-CTには"adenocarcinoma"で始まる用語が63 (及びその語をフレーズの2番目のパートととして含む用語が171) あり、いくつかは共通の親に対する子となっている。にもかかわらず、これらの用語は単一の共通の親を持つわけでは全くなく、選択はどの用語がクエリの意図に合致しているかによらねばならない。もし過去のなんらかの"腺癌(adenocarcinoma)"の診断を見つけ出すことが目的ならば、少なくとも"肺腺癌(adenocarcinoma of lung)" [snomed-ct::254626006] や "肝腺癌(... of liver)"といった形式の用語が含まれなければならない。これらは"診療所見"のヒエラルキーの内側にあり、後2者のような用語の使用は、たとえば"腺癌のおそれ"とか"腺癌のわずかなリスク"といった、記録中の同一用語の他の使用にはマッチされないことを確認すべきである。このような正しいマッチングは、アプリケーション・ソフトウェア及び/またはユーザが最初にデータを生成する際のSNOMED-CT用語の正しい使用に完全に依存している。あるアプリケーションがデータ(openEHRデータを含む)を {"主病名", [snomed-ct::35917007] ("腺癌")} 及び {"部位", "肺"} といった2つの名前/値の対の形式でセーブするというようなことは容易に想像できる。 "肺腺癌" [snomed-ct::254626006] によるクエリは、それがまさにデータの意味するところであるにもかかわらず、フェイルするであろう。このようなデータは誤りではないが、教訓は明白である。データのコード化とクエリにおけるコードの使用は共通のモデルによって統制されなければならない。さもなければ、データ処理の信頼性についての希望はない。
Querying through EHR data is frequently cited to be the major utility of terminology with respect to health information. With the mappings defined in archetypes, a number of approaches are possible, however the semantics of the intended query need to be understood first. Consider a query for "adenocarcinoma" on a patient record. SNOMED-CT includes 63 terms beginning with "adenocarcinoma" (and 171 terms which include the word as a secondary part of the phrase), some as children of a common parent. Nevertheless, the terms do not all have a single common parent; a choice has to be made of which terms correspond to the intent of the query. If it is to find any previous diagnosis of "adenocarcinoma", then at least the terms of the form "adenocarcinoma of lung" [snomed-ct::254626006], "... of liver" have to be included. These are within the "clinical finding" hierarchy, so the use of these latter terms should ensure that matches are not made with other uses of the same terms in the record, e.g. "fear of adenocarcinoma" or "minimal risk of adenocarcinoma". Such correct matching is completely dependent upon the correct use of SNOMED-CT terms in the first place by the software application and/or user creating the data. It is easy to imagine an application that saves data (including openEHR data) in the form of two name/value pairs: {"principal diagnosis", [snomed-ct::35917007] ("adenocarcinoma")} and {"site", "lung"}. Querying using "adenocarcinoma of lung" [snomed-ct::254626006] will fail, even though this is exactly the meaning of the data. The data are not wrong as such, but the lesson is clear: coding of data and code use in queries must be governed by common models, otherwise there is no hope of reliably processing the data.
openEHRのアプローチでは、 (たとえば) " problem-diagnosis-histological_stagingアーキタイプに基づくEVALUATION"を、"診療所見"に一致またはこれに包摂され、"腺癌"に一致またはこれに包摂される /data/items[at0002.1.1]/value/code (histological diagnosis) というパスの値によって特定する、といったことのために、パス・ベースのクエリを用いることができる。
Under the openEHR aproach, path-based querying can be used to specify (for example): "EVALUATIONs based on a problem-diagnosis-histological_staging archetype" with a value at the path /data/items[at0002.1.1]/value/code (histological diagnosis) equal-to-or-subsumed-by "clinical finding" and equal-to-or-subsumed-by "adenocarcinoma".
ここでの仮定は、そのパスがとられたアーキタイプによってパスの値がもともと制約を受けていたということであり、{is-a "診療所見" and is-a "異常な形態上のしこり"} といったリレーションに適合できているということである。肺の腺癌についてのいかなる所見も、最終的に包摂ヒエラルキーによって導出される。他の"腺癌"の用語が誤ってその位置に用いられることはない。
The assumption here is that the value at this path was originally restricted by the archetype from which the path is taken, to conforming to the relation {is-a "clinical finding" and is-a "abnormal morphological mass"}. Any finding of adenocarcinoma of the lung is then forced to be from the resulting subsumption hierarchy; other "adenocarcinoma" terms cannot be wrongly used in this position.
だが、アーキタイプがこのような方法で値に制約をかけていなくとも、同じパス上ですべての"腺癌"という用語を探索する同一のクエリは、それがアーキタイプの唯一の使用であるがゆえに、"過去の腺癌の診断"を見つけるために合理的に用いることができる。同様に、アーキタイプ・ベースのクエリは、29ページのセクション6.4で記述したような、発生しうる他のあいまいさを識別するために用いることができる。
However, even if the archetype had not restricted the value in this way, the same query which searched for any "adenocarcinoma" term at the same path could reasonably be used to locate "previous diagnoses of adenocarcinoma", since this is the only use of the archetype. In a similar way, archetype path-based querying can be used to distinguish the other potential ambiguities described in section 6.4 on page 29.
FootNote(1) http://svn.openehr.org/specification/TRUNK/publishing/architecture/terminology.pdf
FootNote(2) http://svn.openehr.org/specification/TRUNK/publishing/architecture/computable/terminology/terminology.html
FootNote(3) アプガーは、新生児の健康状態についての基本的な尺度であり、出生後2~3回にわたり計測され、0~10点のスコアで与えられる。
FootNote(4) アプガー・アーキタイプについては、以下を参照 http://svn.openehr.org/knowledge/archetypes/dev/html/en/openEHR-EHR-OBSERVATION.apgar.v1.html
3Apgar is a basic measure of health of a newborn, taken 2 or 3 times after delivery, in the form of a 0-10 score.
4See Apgar archetype - http://svn.openehr.org/knowledge/archetypes/dev/html/en/openEHR-EHR-OBSERVATION.apgar.v1.html
Attachments (3)
- terminology2.gif (33.1 KB ) - added by 16 years ago.
- terminology3.gif (45.7 KB ) - added by 16 years ago.
- terminologya.gif (62.3 KB ) - added by 16 years ago.
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip