
| Version 6 (modified by , 16 years ago) ( diff ) |
|---|
TOC PREV NEXT TOC この文書はArchtectural Overviewの14 Integrating openEHR with other Systemsの翻訳である。正確性については保証しないので,適宜原文を参照すること
14 openEHRと他システムとの統合
14 Integrating openEHR with other Systems
14.1 概要
14.1 Overview
EHRとデータを授受できることは、openEHRが満たすべき最も基本的な要求事項のひとつである。"まっさら"(新規開発)の状況下において、openEHRのEHR APIを用いたGUIアプリケーションから生成されたデータを取り扱うならば、何ら問題はない。なぜならネイティブのopenEHRの構造とセマンティクスが用いられるのであるから。それ以外のほとんどすべての状況では、既存のデータ・ソースやシンクを考慮する必要がある。一般的に、外部または"レガシー"データ(ここでは便宜的にこう呼ぶが、当該システムの年代や品質についてなんら暗示するものではない)は、openEHRのデータとは異なった文法上及びセマンティクス上の形式を持っており、シームレスな変換のためには両レベルに着目する必要がある。
Getting data in and out of the EHR is one of the most basic requirements openEHR aims to satisfy. In "greenfield" (new build) situations, and for data being created by GUI applications via the openEHR EHR APIs, there is no issue, since native openEHR structures and semantics are being used. In almost all other situations, existing data sources and sinks have to be accounted for. In general, external or `legacy' data (here the term is used for convenience, and does not imply anything about the age or quality of the systems in question) have different syntactic and semantic formats than openEHR data, and seamless conversion requires addressing both levels.
既存のデータ・ソース及びシンクには、リレーショナル・データベース、HL7v2メッセージ、HL7 CDAドキュメント及びおそらくはCEN EN13606データが含まれる。HL7v2メッセージは、多くの国で病理のメッセージとして最も普及したソースの一つと思われる。EDIFACTメッセージもまた別の例である。ごく最近では、HL7v2メッセージは、紹介状や退院サマリーのためにさえも設計されている。すべてのレガシー・システムが標準に準拠しているわけではなく、たいていの病院や診療所向け製品は独自のデータ・モデルやターミノロジーを保有している。
Existing data sources and sinks include relational databases, HL7v2 messages, HL7 CDA documents and are likely to include CEN EN13606 data. HL7v2 messages are probably one of the most common sources of pathology messages in many countries; EDIFACT messages are another. More recently, HL7v2 messages have been designed for referrals and even discharge summaries. Not all legacy systems are standardised; most hospital and GP products have their own private models of data and terminology usage.
レガシー・データに関して第一に必要なことは、多数の相互に互換性のないソースからのデータを、単一の、標準に準拠した、患者中心のEHRへと変換し、個別の患者について縦方向に照会・検索可能とすることである。そのことで、一般臨床医や専門医による記述、診断及び治療計画は、多様なソースからの検査結果、患者のメモ、医事データ等々と統合可能となり、患者の履歴についての一貫性のあるレコードが供給されるようになる。
The primary need with respect to legacy data is to be able to convert data from multiple mutually incompatible sources into a single, standardised patient-centric EHR for each patient, that can then be longitudinally viewed and queried. This is what enables GP and specialist notes, diagnoses and plans to be integrated with laboratory results from multiple sources, patient notes, administrative data and so on, to provide a coherent record of the patient journey.
技術的な観点からは、多種の非互換性を取り扱わなければならない。入力されるトランザクションとターゲットとなるopenEHRの構造のスコープが対応している保証はない。例えば、ある入力ドキュメントは、複数のクリニカル・アーキタイプに対応しているかもしれない。ターゲット・アーキタイプで定義されるものに比べて一般的には浅い階層構造をもつであろうレガシー・データ(特にメッセージ)は、通常は構造と対応しない。ターミノロジーの使用は、既存のレガシー・システムやメッセージでは極度に多様であり、これもなんとかしなければならない。データ型もまた直接的には対応しておらず、それゆえ、例えば"110/80mmHg"といった入力ストリングとターゲットopenEHR形式における2つのDV_QUANTITYオブジェクトのそれぞれの固有値や単位との間のマッピングといったことが必要となるのである。
In technical terms, a number of types of incompatibility have to be dealt with. There is no guarantee of correspondence of scope of incoming transactions and target openEHR structures - an incoming document for example might correspond to a number of clinical archetypes. Structure will not usually correspond, with legacy data (particularly messages) usually having flatter structures than those defined in target archetypes. Terminology use is extremely variable in existing systems and messages, and also has to be dealt with. Data types will also not correspond directly, so that for example, a mapping between an incoming string "110/80 mmHg" and the target openEHR form of two DV_QUANTITY objects each with their own value and units has to be made.
14.2 統合アーキタイプ
14.2 Integration Archetypes
統合問題に取り組むための基本は、2種のアーキタイプを用いることである。これまでこの文書において、"アーキタイプ"とは主にクリニカル、デモグラフィックまたは事務処理的な用途に"設計された"アーキタイプ(以下「デザイン・アーキタイプ」という)を意味するものであった。このようなアーキタイプすべてに共通する要素とは、 · これらは、リファレンス・モデルの主要部分、なかんずくOBSERVATION、EVALUATION、INSTRUCTION及びACTIONといったエントリー・サブタイプに基づいており、 · 各分野の専門家によってスクラッチから意識的に設計されたうえで、openEHRアーキタイプの既存のライブラリーに統合されたものであり、 · 観察タイプ、人格タイプ等といったアイデンティファイ可能な健康"概念"ごとにひとつのアーキタイプがあることである。
The foundation of a key approach to the integration problem is the use of two kinds of archetypes. So far in this document "archetypes" has meant "designed" archetypes, generally clinical, demographic or administrative. The common factors for all such archetypes are:
- they are based on the main part of the reference model, particularly the Entry subtypes OBSERVATION, EVALUATION, INSTRUCTION and ACTION;
- they are consciously designed from scratch by groups of domain specialists, and integrated into the existing library of openEHR archteypes;
- there is one archetype per identifiable health "concept", such as an observation type, person type etc.
アーキタイプの2つ目のカテゴリーは、"統合"アーキタイプである。これらの特徴は、 · これらは、同一のハイレベル・タイプ(COMPOSITION, SECTION等)に基づいているが、GENERIC_ENTRY (EHRインフォメーション・モデル参照)といったエントリー・サブタイプも用いており、 · レガシーまたは既存のデータやメッセージの擬似構造として設計され、従って設計作業は全く異なるやり方で、専ら入力データの構造に通じたIT及びその他の技術者によってなされ、 · EHRへのトランザクションとして意味のあるメッセージ・タイプやアイデンティファイ可能なソース・データごとにひとつの統合アーキタイプがある。
A second category of archetypes is "integration" archetypes. These are characterised as follows:
- they are based on the same high-level types (COMPOSITION, SECTION etc), but use the Entry subtype GENERIC_ENTRY (see EHR Information Model);
- they are designed to mimic the structure of legacy or existing data or messages; the design effort therefore is completely different, and is more likely to be done by IT or other technical staff who are familiar with the structures of the incoming data;
- there is one integration archetype per message type or identifiable source data that makes sense as a transaction to the EHR.
データ統合環境において、データのターゲット構造、コード化及びその他のセマンティクスは常にデザイン・アーキタイプによって定義され、一方統合アーキタイプは外部データをopenEHR環境にマッピングするための手段を提供する。
In the data integration environment, "designed" archetypes always define the target structures, coding and other semantics of data, while "integration" archetypes provide the means mapping of external data into the openEHR environment.
14.3 データコンバージョンのアーキテクチャ
14.3 Data Conversion Architecture
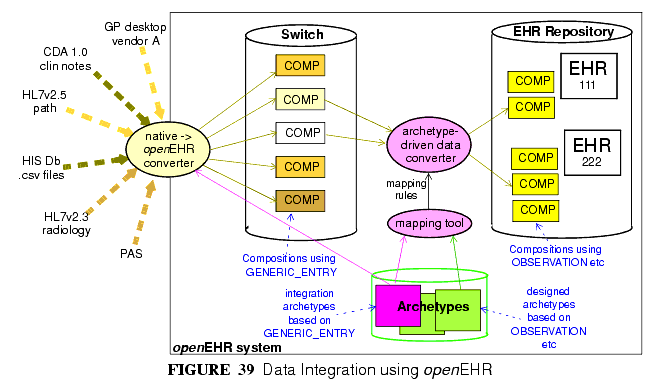
データをopenEHRシステムにインポートするための統合アーキタイプベースの戦略は、図39に示す通り、2つのステップからなる。
The integration archetype-based strategy for importing data into an openEHR system, shown in FIGURE 39, consists of two steps.

まず、openEHR統合スイッチで図示したように、データは原形の文法形式からopenEHRのCOMPOSITION/SECTION/GENERIC_ENTRY構造へと 変換される。たいていのデータは、入力構造(HL7v2の検査メッセージのような)に可能な限り近似した擬似構造として設計された統合アーキタイプの制御のもとで、GENERIC_ENTRYパートで表現される。FEEDER_AUDIT構造は、統合メタ・データを包含するために用いられる。このステップの結果として、openEHRタイプのシステム内で表現され(すなわちopenEHRリファレンス・モデルのインスタンスとして)、通常のopenEHRのソフトウェアで直ちに処理可能なデータを得る。
Firstly, data are converted from their original syntactic format into openEHR COMPOSITION/SECTION/GENERIC_ENTRY structures, shown in the openEHR integration switch. Most of the data will appear in the GENERIC_ENTRY part, controlled by an integration archetype designed to mimic the incoming structure (such as an HL7v2 lab message) as closely as possible; FEEDER_AUDIT structures are used to contain integration meta-data. The result of this step is data that are expressed in the openEHR type system (i.e. as instances of the openEHR reference model), and are immediately amenable to processing with normal openEHR software.
次のステップで、統合及びデザイン・アーキタイプ間のマッピングを用いることによって、セマンティックな変換が機能する。このようなマッピングは、ツールを使用してアーキタイプの作者が生成することができる。マッピング・ルールは、構造的変換、用語やコードの使用及びその他の変更を定義するための鍵となる。もちろん異種システム統合に関するビジネス上の重要な課題はまだ残っている。それらのうちのいくつかは、共通IMに関する文書中のフィーダー・システムについてのセクションで取り扱う。
In the second step, semantic transformation is effected, by the use of mappings between integration and designed archetypes. Such mappings are created by archetype authors using tools. The mapping rules are the key to defining structural transformations, use of terminological codes, and other changes. Serious challenges of course remain in the business of integrating heterogeneous systems; some of these are dealt with in the Common IM document sections on Feeder systems.
Attachments (1)
- integrationa.gif (60.1 KB ) - added by 17 years ago.
{kind=link}
Download all attachments as: .zip