
6 openEHRの EHR設計
この文書はArchtectural Overviewの6 Design of the openEHR EHRの翻訳である。内容の正確性については保証しないので,適宜原文を参照してください。
6 Design of the openEHR EHR
6.1 EHR システム
6.1 The EHR System
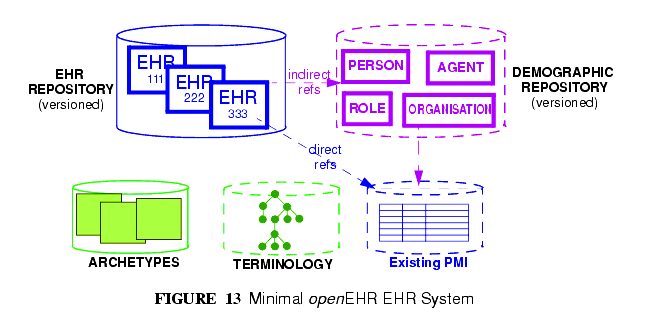
情報という点でいうと,openEHRをベースとした最小限のEHRシステムはEHRのリポジトリで構築されている。それは,図13に示すようにアーキタイプのリポジトリや(もし利用可能であれば)用語体系,デモグラフィック/識別情報からなりたっている。
{kind=link}
In informational terms, a minimal EHR system based on openEHR consists of an EHR repository, an archetype repository, terminology (if available), and demographic/identity information, as shown in FIGURE 13.

後者は既存の患者マスターインデックス(PMI; patient master index)の形式,ほかのディレクトリであり,openEHRのデモグラフィックリポジトリ形式であるかもしれない。openEHRデモグラフィックリポジトリは既存のPMIのフロントエンドとしての役割を果たすこともでき,それ自体で動作することもできる。どちらの方法でもデモグラフィック情報構造と更新管理の標準化という2つの機能を持つ。openEHRのEHRにはその環境で利用するために設定されたデモグラフィックリポジトリのどれにでも対応するエンティティが含まれている。EHRはデモグラフィックデータではなく他の識別情報を元に設定することもできる。openEHRの基本原則の一つは,EHRとデモグラフィック情報を完全の分離することであり、そのためにEHRは所属している患者識別情報をほとんどあるいはまったく持たないように分離されている。セキュリティ上の利点は以下に記述する通りである。より完全なEHRシステムでは,数多くの(特にセキュリティに関連した)他のサービスが通常図7に示すように配備されている。
{kind=link}
The latter may be in the form of an existing PMI (patient master index) or other directory, or it may be in the form of an openEHR demographic repository. An openEHR demographic repository can act as a front end to an existing PMI or in its own right. Either way it performs two functions: standardisation of demographic information structures and versioning. An openEHR EHR contains references to entities in whichever demographic repository has been configured for use in the environment; the EHR can be configured to include either no demographic or some identifying data. One of the basic principles of openEHR is the complete separation of EHR and demographic information, such that an EHR taken in isolation contains little or no clue as to the identity of the patient it belongs to. The security benefits are described below. In more complete EHR systems, numerous other services (particularly security-related) would normally be deployed, as shown in FIGURE 7.
6.2 最上位情報構造
6.2 Top-level Information Structures
今まで述べてきたように、openEHRの情報モデルはさまざまな粒度の情報を定義している。細粒度の構造がデータ構造や共通モデルで利用される支援情報やデータ型で定義されている。これらは,EHR、EHR Extract,デモグラフィックと他の「最上位」モデルの順番で利用されており、後の方のモデルはopenEHRの「最上位構造」を定義している。内容の構造は明確に独立しており,ドキュメント指向システムにおいて分割されたドキュメントと同じように考えてよい。openEHRの情報システムでは、「最上位構造」は一般的にユーザーにとって直接関心が向けられるものである。主要な最上位構造には以下のようなものがある。
As has been shown, the openEHR information models define information at varying levels of granularity. Fine-grained structures defined in the Support and Data types are used in the Data Structures and Common models; these are used in turn in the EHR, EHR Extract, Demographic and other "top-level" models. These latter models define the "top-level structures" of openEHR, i.e. content structures that can sensibly stand alone, and may be considered the equivalent of separate documents in a document-oriented system. In openEHR information systems, it is generally the top-level structures that are of direct interest to users. The major top-level structures include the following:
- Composition - EHRの引き渡し単位(EHR IMのCOMPOSITION型を参照)
- EHR Acces - EHR単位のアクセス管理オブジェクト(EHR IMのEHR_ACCESS型を参照)
- EHR Status - EHRの状態サマリー(EHR IMのEHR_STATUS型を参照)
- Folder hierarchy - EHRやデモグラフィックサービスののディレクトリ構造として働く(Common IMのFOLDER型を参照)
- Party - ActorやRoleなどを含むさまざまなサブタイプ。識別や連絡先情報といったデモグラフィックエンティティを表現する(PARTY型やDemographic IMのサブタイプを参照)
- EHR Extract - EHRシステム間の情報伝達単位であり、EHRをシリアライズしたものや、デモグラフィックなどの情報を持っている(EHR_Extract IMのEHR_EXTRACT型を参照)
- Composition - the committal unit of the EHR (see type COMPOSITION in EHR IM);
- EHR Acces - the EHR-wide access control object (see type EHR_ACCESS in EHR IM);
- EHR Status - the status summary of the EHR (see type EHR_STATUS in EHR IM);
- Folder hierarchy - act as directory structures in EHR, Demographic services (see type FOLDER in Common IM);
- Party - various subtypes including Actor, Role, etc. representing a demographic entity with identity and contact details (see type PARTY and subtypes in Demographic IM);
- EHR Extract - the transmission unit between EHR systems, containing a serialisation of EHR, demographic and other content (see type EHR_EXTRACT in EHR Extract IM).
All persistent openEHR EHR, demogr[http://www.openehr.jp/attachment/wiki/Archtectural%20Overview%20Design%20of%20the%20openEHR%20EHR/aphic and related content is found within top-level information structures. Most of these are visible in the following figures.
6.3 EHR
6.3 The EHR
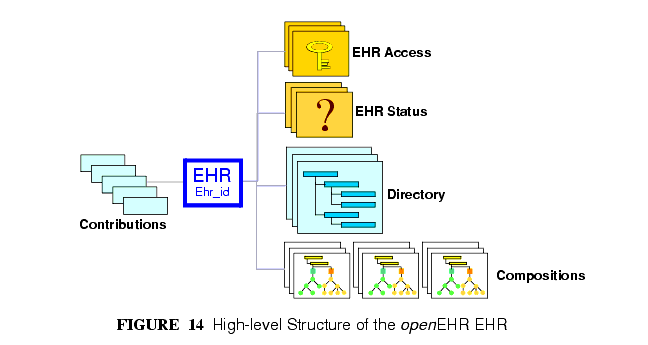
openEHRのEHRは比較的単純なモデルにしたがって構造化されている。EHR IDで識別されるEHRの中心オブジェクトは,構造化された数多くの型や更新管理された情報に加えて、EHRへの変更を監査する役割のあるCONTRIBUTIONオブジェクトのリストへの参照を指定している。図14にopenEHRのEHR高次構造が示されている。
{kind=link}
The openEHR EHR is structured according to a relatively simple model. A central EHR object identified by an EHR id specifies references to a number of types of structured, versioned information, plus a list of Contribution objects that act as audits for changes made to the EHR. The high-level structure of the openEHR EHR is shown in FIGURE 14.

この図では、EHRの各部を以下のように示している。
In this figure, the parts of the EHR are as follows:
- EHR: 基底オブジェクトであり、全体で一意のEHR識別子で識別される
- EHR_access (versioned): レコードへのアクセス管理設定を持つオブジェクト
- EHR_status (versioned): さまざまな状態や管理情報を持つオブジェクト。現在関連のあるレコード(例えば患者)を対象とした識別子をもつこともある。
- DIRECTORY (versioned): COMPOSITIONを論理的に整理するために使える任意に階層的な構造を持つFOLDER
- COMPOSITION (versioned): 全ての臨床や管理のためのレコードの内容についてのコンテナ
- CONTRIBUTION : 健康記録に変更が加えられるたびに作成される変更記録。各CONTRIBUTIONはユーザーにより付託されるかともに保証されたレコードの中の更新管理された任意のアイテムの一つあるいはそれ以上のVERSIONを参照している。
- EHR: the root object, identified by a globally unique EHR identifier;
- EHR_access (versioned): an object containing access control settings for the record;
- EHR_status (versioned): an object containing various status and control information, optionally including the identifier of the subject (i.e. patient) currently associated with the record;
- Directory (versioned): an optional hierarchical structure of Folders that can be used to logically organise Compositions;
- Compositions (versioned): the containers of all clinical and administrative content of the record;
- Contributions: the change-set records for every change made to the health record; each Contribution references a set of one or more Versions of any of the versioned items in the record that were committed or attested together by a user to an EHR system.
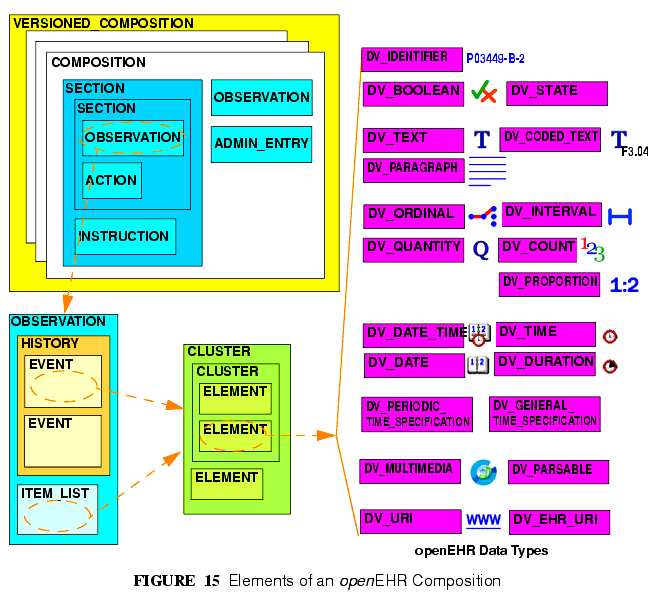
DIRECTORYオブジェクトにしたがいCOMPOSITIONの内部構造はCEN EN13606やHL7 CDA標準のような国際的に承認された健康情報のレベルに密接に対応している。臨床やレコードの管理のために必要な全てのデータ型のために21のデータ型が提示されている。
The internal structure of the Composition along with the Directory object correspond closely to the levels in internationally agreed models of health information such as the CEN EN13606 and HL7 CDA standards.
The logical structure of a typical Composition is shown in more detail in FIGURE 15. In this figure, the various hierarchical levels from Composition to the data types are shown in a typical arrangement. The 21 data types provide for all types of data needed for clinical and administrative recording.
6.4 エントリーと「臨床記述」
6.4 Entries and "clinical statements"
Entryサブタイプ
Entry Subtypes
突き詰めて言うと,openEHRのEHRで作成される臨床情報は全て「Entry」として表現される。Entryは論理的には、1つの「臨床記述」であって、簡単で短くわかりやすいフレーズであるが、重要な意味を多く含んでもいる。例えば、微生物検査結果全体や、心理学的検査記録、複雑な処方オーダーなど。実際の意味において、Entryクラスはレコードにおける「ハード」な情報すべてのセマンティクスを定義しているため、openEHRのEHR情報モデルでもっとも重要なものである。これらはアーキタイプ化されることを目的としており、実際にEntryのためのアーキタイプとEntryの一部はEHRのために定義されたアーキタイプの非常に大きな部分を占めている。
All clinical information created in the openEHR EHR is ultimately expressed in "Entries". An Entry is logically a single clinical statement', and may be a single short narrative phrase, but may also contain a significant amount of data, e.g. an entire microbiology result, a psychiatric examination note, a complex medication order. In terms of actual content, the Entry classes are the most important in the openEHR EHR Information Model, since they define the semantics of all the hard' information in the record. They are intended to be archetyped, and in fact, archetypes for Entries and sub-parts of Entries make up the vast majority of archetypes defined for the EHR.
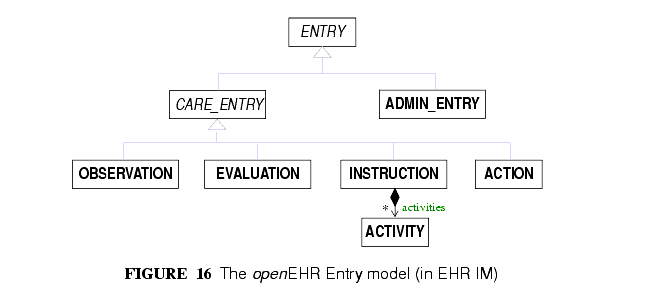
openEHRのENTRYクラスは図16に示されている。ADMIN_ENTRY、OBSERVATION、EVALUATION、INSTRUCTION、ACTIONの5つの具象サブタイプがあり,後ろ4つはCARE_ENTRYの種類でもある。
The openEHR ENTRY classes are shown in FIGURE 16. There are five concrete subtypes: ADMIN_ENTRY, OBSERVATION, EVALUATION, INSTRUCTION and ACTION, of which the latter four are kinds of CARE_ENTRY.

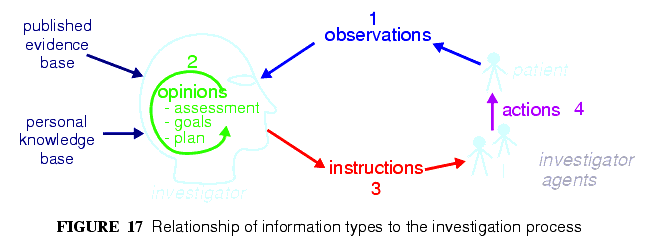
これらの型は図17に示すように臨床上の問題解決プロセスを元にした選択をベースにしている。
The choice of these types is based on the clinical problem-solving process shown in FIGURE 17.

この図では、臨床医学だけではなく、一般科学においても典型的な対話的問題解決プロセスで、情報が作成されるサイクルを示している。全体としての「システム」は、「患者システム」(patient system)と「臨床調査システム」(clinical investigator system)の2つの部分で構成されている。後者は医療従事者で構成されているが、患者を含むこともあり(患者が観察的行動や治療的行動を行っている場合)、患者システムの状態を理解し,ケアを提供することに関与する。問題は、観察し、意見(仮説)を出し、次のステップのために行動を処方(指示)することで解決される。その結果,更なる調査が行われたり問題を解決するために計画された調査が行われたりして、指示(行動)が実施される。
This figure shows the cycle of information creation due to an iterative, problem solving process typical not just of clinical medicine but of science in general. The "system" as a whole is made up of two parts: the "patient system" and the "clinical investigator system". The latter consists of health carers, and may include the patient (at points in time when the patient performs observational or therapeutic activities), and is responsible for understanding the state of the patient system and delivering care to it. A problem is solved by making observations, forming opinions (hypotheses), and prescribing actions (instructions) for next steps, which may be further investigation, or may be interventions designed to resolve the problem, and finally, executing the instructions (actions).
このプロセスモデルはLawrence WeedのEHR記録における「問題指向」(problem-oreinted)をはじめ、あとで関連する業績として、Rector, Nowland, KayによるモデルFootNote(Rector A L, Nowlan W A, Kay S. Foundations for an Electronic Medical Record. The IMIA Yearbook of Medical Informatics 1992 (Eds. van Bemmel J, !McRay A). Stuttgart Schattauer 1994.)や「仮説演繹」推論モデルFootNote(Elstein AS, Shulman LS, Sprafka SA. Medical problem solving: an analysis of clinical reasoning. Cambridge, MA: Harvard University Press, 1978)を合成して作られている。しかしながら、仮説をたてて検証していくことは臨床家にとって唯一の成功のためのプロセスではない。エビデンスは(年齢が高く経験を積んでいるほど)パターン認識に大きく依存しており、以前に経験した同じような患者やプロトタイプモデルで使われたプランを直接利用することがある。openEHRで使われている調査プロセスモデルは、認知論的手法にも準拠している。なぜなら、意見がどのように形成されるのか,結論までにどれくらいプロセスを繰り返さなければいけないのか、繰り返しの間に存在する全てのステップが要求されるかどうかさえも明らかにされていないからである。(例えば,一般内科医(General Physician)は確定診断に至る前に薬剤を処方することがよくある)つまり,openEHRのEntryモデルはプロセスモデルを押し付けるものではなく,起こりうる情報がとりうる型をあらわしている。
This process model is a synthesis of Lawrence Weed's "problem-oriented" method of EHR recording, and later related efforts, including the model of Rector, Nowlan & Kay [7], and the "hypothetico-deductive" model of reasoning (see e.g. [3]). However hypothesis-making and testing is not the only successful process used by clinical professionals - evidence shows that many (particularly those older and more experienced) rely on pattern recognition and direct retrieval of plans used previously with similar patients or prototype models. The investigator process model used in openEHR is compatible with both cognitive approaches, since it does not say how opinions are formed, nor imply any specific number or size of iterations to bring the process to a conclusion, nor even require all steps to be present while iterating (e.g. GPs often prescribe without making a firm diagnosis). Consequently, the openEHR Entry model does not impose a process model, it only provides the possible types of information that might occur.
Entry型のオントロジー
Ontology of Entry Types
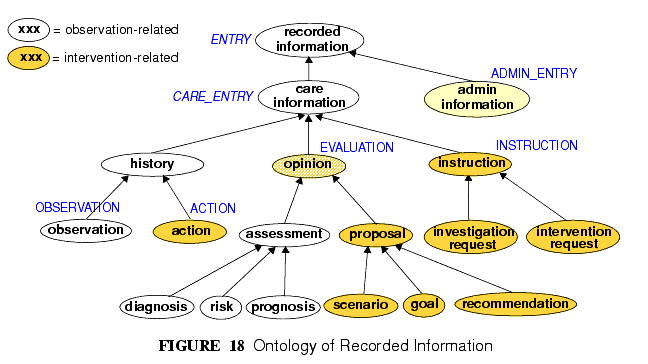
実地臨床の世界では前述のENTRYのサブタイプに対応するたった5種類のデータに基づいて考えられているわけではない。これらの型それぞれにサブタイプがたくさんあり,その中のいくつかは図18にオントロジーが示されている。
In the clinical world practitioners do not think in terms of only five kinds of data corresponding to the subtypes of Entry described above. There are many subtypes of each of these types, of which some are shown in the ontology of FIGURE 18.

最上位の重要なカテゴリは「ケア情報(care information)」と「管理情報(administrative information)」である。ケア情報カテゴリにはケアプロセスの任意の時点で記録される可能性のあるすべての命令文を網羅しており,Entryモデルの基礎となっている主要なサブカテゴリである「観察(observation)」、「見解(opinion)」、「指示(instruction)」、「行動(action)」(ある種の観察)も含んでいる。これらは過去や現在、そして未来の時点にも対応している。管理情報カテゴリはケアプロセスだけで生成されていないが、それを組織化するのに関連するような予約や入院と言ったことに関する情報を網羅している。この情報はケアに関するものではないが,ケアを提供するための後方支援に関連している。
The key top-level categories are care information' and administrative information'. The former encompasses all statements that might be recorded at any point during the care process, and consists of the major sub-categories on which the Entry model is based, namely observation', opinion', instruction', and action' (a kind of observation) which themselves correspond to the past, present and future in time. The administrative information category covers information which is not generated by the care process proper, but relates to organising it, such as appointments and admissions. This information is not about care, but about the logistics of care delivery.
これらの多様性にも関わらず、結局のところこの図に示された末節のカテゴリのそれぞれはプロセスモデルの型の一つ、つまりopenEHRのEntryモデルのサブタイプからなるサブカテゴリとなっている。
Regardless of the diversity, each of the leaf-level categories shown in this figure is ultimately a subcategory of one of the types from the process model, and hence, of the subtypes of the openEHR Entry model.
特定(こでの場合は評価)のEntryサブタイプに関連のある関心についての情報(例えば、リスク評価)を表現するために設計されたアーキタイプを利用することで、オントロジー由来のカテゴリーを正確に表現することができるようになる。Entryがこのようにモデル化されたシステムでは、多様な種類のEntryを誤って識別する危険性がなく、Entryのサブタイプや時間、確定性/否定も同様に配慮される。図18のオントロジーが正確なものではなくても、アーキタイプはそのようなカテゴリーが実際にあるべき改良された概念を扱うように構築されることに注意すべきである。
{kind=link}
Correct representation of the categories from the ontology is enabled by using archetypes designed to express the information of interest (say a risk assessment) in terms of a particular Entry subtype (in this case, Evaluation). In a system where Entries are thus modelled, there will be no danger of incorrectly identifying the various kinds of Entries, as long as the Entry subtype, time, and certainty/negation are taken into account. Note that even if the ontology of FIGURE 18 is not correct (undoubtedly it isn't), archetypes will be constructed to account for each improved idea of what such categories should really be.
臨床記述の状態と否定
Clinical Statement Status and Negation
診療情報を記録する際によく知られている問題は、記録された事項の状態をどのように割り当てるかということである。「Pの実測値」(Pはある現象を現す)「Pの家族歴」「Pのリスク」「Pのおそれ」や、これらの否定(例えば「Pではないもの」「Pの履歴なし」など)についても同様に多様な状態についての表現がある。このように一般に表現される状態を適切に分析してみると、これらは「状態」といえるものではなく、図18に示されるオントロジーのような情報の別のカテゴリーである。一般に、否定は適切なEntry型の「除外(exclusion)」アーキタイプを利用して扱われる。例えば、「アレルギーなし」はこの患者からアレルギーが除外されると表現する評価(Evaluation)アーキタイプを使ってモデル化することができる。別の状態を示す型の組み合わせは、例えば「(5年前の)大腿骨頭置換術」、「大腿骨頭置換術(推奨される)」、「大腿骨頭置換術(来週の火曜日午前10時に予定されている)」といった介入に関連した情報をシステム内で適切にモデル化することができずに混乱している。
A well-known problem in clinical information recording is the assignment of "status" to recorded items. Kinds of status include variants like "actual value of P" (P stands for some phenomenon), "family history of P", "risk of P", "fear of P", as well as negation of any of these, i.e. "not/no P", "no history of P" etc. A proper analysis of these so called statuses shows that they are not "statuses" at all, but different categories of information as per the ontology of FIGURE 18. In general, negations are handled by using "exclusion" archetypes for the appropriate Entry type. For example, "no allergies" can be modelled using an Evaluation archetype that describes which allergies are excluded for this patient. Another set of statement types that can be confused in systems that do not properly model information categories concern interventions, e.g. "hip replacement (5 years ago)", "hip replacement (recommended)", "hip replacement (ordered for next tuesday 10 am)".
これらを記述するすべての型はopenEHRのEntry型の一つに曖昧ではない形式で直接マッピングすることができる。EHRの問い合わせが、問題のある現象に対する観察についての問い合わせがなされたときにリスクや恐れがあるといった記載のような正確でないデータにマッチしないように保証するものである。
All of these statement types map directly to one of the openEHR Entry types in an unambiguous fashion, ensuring that querying of the EHR does not match incorrect data, such as a statement about fear or risk, when the query was for an observation of the phenomenon in question.
openEHRの臨床情報モデルのより詳細な内容については、EHR IMについての文書のEntryセクションにある。
Further details on the openEHR model clinical information are given in the EHR IM document, Entry Section.
6.5 介入の管理
6.5 Managing Interventions
介入プロセスについての重要な部分は図17に示されており、ヘルスケアは一般的には「介入」そのものである。介入が「未来時間」(介入する行動が、特定の時間で分岐したり繰り返したりするなどを表現しなくてはならず、単純で直線的ん時間軸で観察されるものではないからである)であったり、予定されていないイベントにより物事が変化し、行われた介入の状態によっては、(特に分散されたシステムでは)その後の追跡が困難になることから、介入を指定し、管理することは(もっとも単純な処方や複雑な手術であろうとも)情報システムにとって難しい課題である。
{kind=link}

A key part of the investigation process shown in FIGURE 17, and indeed healthcare in general, is intervention. Specifying and managing interventions (whether the simplest prescriptions or complex surgery and therapy) is a hard problem for information systems because it is in "future time" (meaning that intervention activities have to be expressed using branching/looping time specifications, not the simple linear time of observations), unexpected events can change things (e.g. patient reaction to drugs), and the status of a given intervention can be hard to track, particularly in distributed systems.
しかしながら、医療従事者の視点では、どのような投薬が患者になされているのか、その時点でどのようなことが進行しつつあるのかについて把握しようとすることはもっとも基本的なことである。
However, from the health professional's point of view, almost nothing is more basic than wanting to find out: what medications is this patient on, since when, and what is the progress?
これらの取り組みに対するopenEHRのアプローチではEntry型のINSTRUCTIONを使ったり、未来の介入を指定するためにACTIVITYの一部を用いたり、Entry型のサブタイプであるACTIONを使って実際に何が起こったのかを記録していく。このモデルには以下に示す多くの重要な特徴がある。
The openEHR approach to these challenges is to use the Entry type INSTRUCTION, its subpart ACTIVITY to specify interventions in the future, and the Entry subtype ACTION to record what has actually happened. A number of important features are provided in this model, including:
- すべての介入に対して単純で柔軟なモデリングを行う。単純な薬を投薬する指示であったり複雑な病院で行われるような治療であっても対応できるように
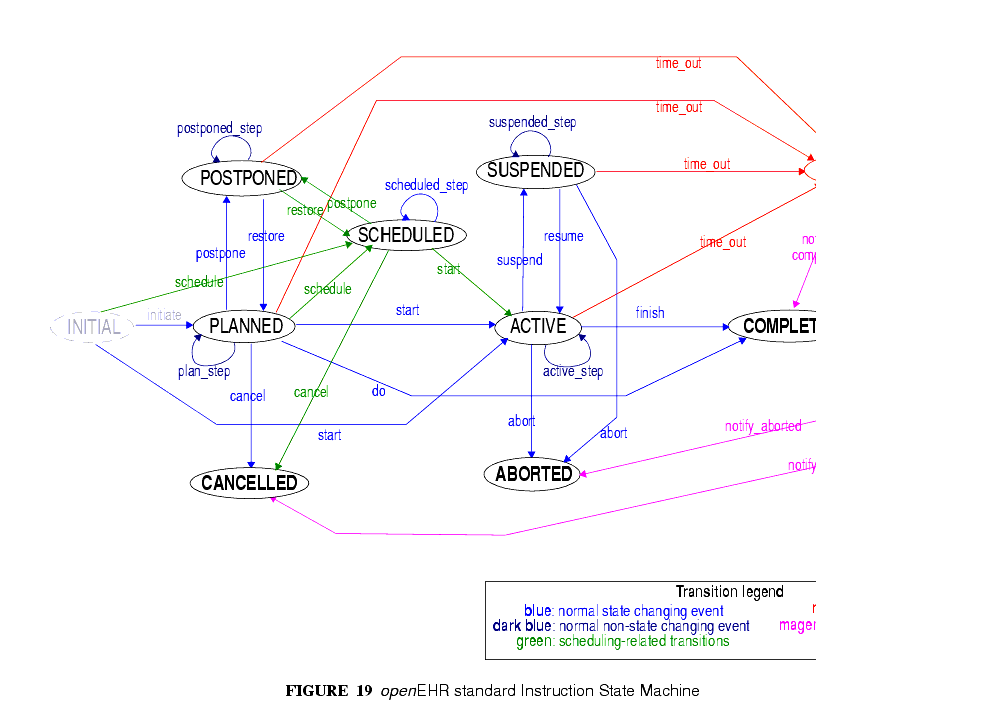
- 図19に示される標準状態機械にある状態で任意の介入の状態を認識する手法。これにより患者のEHRを標準的な手法で「現在投与されているすべて薬剤」、「中断されているすべての介入」などを求める問い合わせを行うことができる。
- 特定のケアプロセスの手順を標準状態機械での状態により流れを示すことに対応させ、医療従事者に彼らが理解する用語で介入を定義することができる。
- それを求めることなく業務手順を自動化することを支援する。
{kind=link}
- a single, flexible way of modelling all interventions, whether they be single drug medication orders or complex hospital-based therapies;
- a way of knowing the state of any intervention, in terms of the states in a standard state machine, shown in FIGURE 19; this allows a patient's EHR to be queried in a standard way so as to return "all active medications", "all suspended interventions" etc.;
- a way of mapping particular care process flow steps to the standard state machine states, enabling health professionals to define and view interventions in terms they understand;
- support for automated workflow, without requiring it.
openEHRのわかりやすい更新管理能力と、INSTRUCTION/ACTIONの設計のおかげで、分散環境において臨床家に定義すべき記録や、患者に対する介入を管理することができるようになっている。
Coupled with the comprehensive versioning capabilities of openEHR, the Instruction/Action design allows clinical users of the record to define
and manage interventions for the patient in a distributed environment.
6.6 EHRでの時間
6.6 Time in the EHR
時間は健康情報をモデル化する際の取り組むべき問題点として知られている。openEHRでは、今までに述べられてきた調査プロセスの副産物である時間(例えば、検体を採取した時間や集めた時間、測定した時間、ヘルスケア業務の出来事が起きた時間、データが登録された時間)は具体的にモデル化されていて、特定の内容に限定された他の時間(例えば、発症した日や転帰日)は汎用データ属性をアーキタイプ化することでモデル化されつつある。次の図は典型的な観察プロセスについての時間とopenEHRの参照モデルにおいて対応する属性との関係を示している。GPの診察や放射線レポートや他のものであるなどの異なるシナリオにおいては、一時的な関係は図に示されているものとはまったく異なることに注意すべきである。時間はEHR情報モデル文書(EHR Infomation Model document)に詳しく記載されている。
{kind=link}
Time is well-known as a challenging modelling problem in health information. In openEHR, times that are a by-product of the investigation process (e.g. time of sampling or collection; time of measurement, time of a healthcare business event, time of data committal) described above are concretely modelled, while other times specific to particular content (e.g. date of onset, date of resolution) are modelled using archetyping of generic data attributes. The following figure shows a typical relationship of times with respect to the observation process, and the corresponding attributes within the openEHR reference model. Note that under different scenarios, such as GP consultation, radiology reporting and others, the temporal relationships may be quite different than those shown in the figure. Time is described in detail in the EHR Information Model document.

6.7 言語
6.7 Language
ある状況においては、EHRで複数の言語が使われることもある。患者が国境をこえて治療を受けにきたり(スカンジナビア諸国間や、ブラジルとその北側の隣国との間ではよくあることである)、治療を受けている患者が旅行をしていたり、単にその環境で複数の言語が利用されているからでもある。
In some situations, there may be more than one language used in the EHR. This may be due to patients being treated across borders (common among the Scandinavian countries, between Brazil and northern neighbours), or due to patients being treated while travelling, or due to multiple languages simply being used in the home environment.
言語はopenEHRのEHRでは以下のように扱われている。EHR全体でにおいてOSのロケールに応じてデフォルトの言語が決定される。もし、必要であればEHR_statusオブジェクトでロケール指定することができる。
Language is handled as follows in the openEHR EHR. The default language for the whole EHR is determined from the operating system locale. It may be included in the EHR_status object if desired.
次に言語は強制的にEHRデータの二つの場所で指定される。つまり、COMPOSITIONとEntry(例えばObservationなど)のlanguage属性である。こうすることで、EHRで異なる言語を同一のCOMPOSITIONで使うことができ、同じCOMPOSITIONにある複数のエントリーで異なる言語を利用することができる。さらに、Entry内部でテキストやコード化されたテキストといった項目はEntry内部での言語と違うものであれば、その言語で記録することも出来、これらの型は言語を指定しなくてもよいEntry型以外の構造で使われることもある。
Language is then mandatorily indicated in two places in the EHR data, namely in Compositions and Entries (i.e. Observations, etc), in a language attribute. This allows both Compositions of different languages in the EHR, and Entries of different languages in the same Composition. Additionally, within Entries, text and coded text items may optionally have language recorded if it is different from the language of the enclosing Entry, or where these types are used within other non-Entry structures that don't indicate language.
実際の多言語環境は、いくつかの場面において臨床で遭遇する内容ではあるが、これらの特徴は翻訳の時にもっともよく利用される。翻訳の場合にはEHRのある部分(例えば、特定のCOMPOSITION)が臨床で起こることの前後でEHRの第一言語で利用できる情報に翻訳するために利用される。(他のEHRとの交流のような場面での)翻訳作業では記録を新しいVERSION形式に変更することもある。新しい翻訳はVERSIONのブランチとして便利に記録することが出来、翻訳のVERSIONを付け加えることができる。これは強制されるものではないが、大本の内容を置換することなく翻訳を記録する便利な方法を提供している。
The use of these features is mostly likely to occur due to translation, although in some cases a truly multi-lingual environment might exist within the clinical encounter context. In the former case, some parts of an EHR, e.g. particular Compositions will be translated before or after a clinical encounter to as to make the information available in the primary language of the EHR. The act of translation (like any other interaction with the EHR) will cause changes to the record, in the form of new Versions. New translations can conveniently be recorded as branch versions, attached to the version of which they are a translation. This is not mandatory, but provides a convenient way to store translations so that they don't appear to replace the original content.
Attachments (8)
- design_of_ehr8.gif (36.6 KB ) - added by 17 years ago.
- design_of_ehra.gif (33.0 KB ) - added by 17 years ago.
- design_of_ehr5.gif (107.3 KB ) - added by 17 years ago.
- design_of_ehr4.gif (18.3 KB ) - added by 17 years ago.
- design_of_ehr2.gif (26.7 KB ) - added by 17 years ago.
- design_of_ehr3.gif (43.3 KB ) - added by 17 years ago.
- design_of_ehr7.gif (73.9 KB ) - added by 17 years ago.
- design_of_ehr6.gif (26.6 KB ) - added by 17 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip