
| Version 35 (modified by , 16 years ago) ( diff ) |
|---|
TOC PREV NEXT TOC この文書はArchtectural Overviewの10 Archetypes and Templatesの翻訳である。内容の正確性については保証しないので,正確な内容については原文を参照すること
10 アーキタイプとテンプレート
10 Archetypes and Templates
10.1 概要
10.1 Overview
2段階のモデル化の過程においては、情報の構造化を形式的に定義する場面でも2段階のレベルが生じる。下位のレベルは参照モデルのレベルであり、この参照モデルというオブジェクトモデル object model においてソフトウェアとデータが生成される。openEHRの参照モデルでの概念は固定されたものであり、コンポジション Composition、セクション Section、オブザベーション Observation、ならびに量 Quantity やコード化テキスト Coded text などの様々なデータ型を含む。上位のレベルはアーキタイプとテンプレートの形式で定式化されたドメインレベルの定義である。このレベルで定義された概念は、例えば、「血圧測定」とか「SOAPの表題」とか「HbA1Cの結果」などになる。
Under the two-level modelling approach, the formal definition of information structuring occurs at two levels. The lower level is that of the reference model, a stable object model from which software and data can be built. Concepts in the openEHR reference model are invariant, and include things like Composition, Section, Observation, and various data types such as Quantity and Coded text. The upper level consists of domain-level definitions in the form of archetypes and templates. Concepts defined at this level include things such as "blood pressure measurement", "SOAP headings", and "HbA1c Result".
openEHRの参照モデルに適合する情報とはすなわち情報モデル(IM)の集まりであり、これはデータの生成や修正ならびに照会 query がアーキタイプによって制御されること archetypable を意味する。アーキタイプ自身はデータとは分離されており、独自のレポジトリに格納される。アーキタイプは、それがどこに格納されるにせよ、通常はオンライン上で周知の場所にあるアーキタイプライブラリを含んでいる。 実行時においてアーキタイプはテンプレートによって配置される。そのときテンプレートは、その用途に応じた特定のアーキタイプグループを指定する。その用途はしばしば画面のフォーム screen form に応じたものになるだろう。
All information conforming to the openEHR Reference Model (RM) - i.e. the collection of Information Models (IMs) - is "archetypable", meaning that the creation and modification of the content, and subsequent querying of data is controllable by archetypes. Archetypes are themselves separate from the data, and are stored in their own repository. The archetype repository at any particular location will usually include archetypes from well-known online archetype libraries. Archetypes are deployed at runtime via templates that specify particular groups of archetypes to use for a particular purpose, often corresponding to a screen form.
アーキタイプ自身はアーキタイプモデルのインスタンスであり、アーキタイプモデルはアーキタイプを生成する言語を定義する。その言語はモデルと同等であり、それはアーキタイプ定義言語 ADL と呼ばれる。このような方法は openEHRアーキタイプオブジェクトモデル AOM とADLのドキュメント にそれぞれの仕様が記述されている。おのおののアーキタイプは参照モデルに対する制約を集めたものであり、例えば「検査結果」というアーキタイプはそれによってそのアーキタイプに適合するアーキタイプモデルのインスタンスを定義するものである。ひとつのアーキタイプとは LEGO の命令シート instruction sheet と似たものと考えることができる。例えば、LEGOでトラクターを作った場合、その命令シートは、LEGOのブロックでトラクターを構築する際のLEGOの設定を定義している。アーキタイプには柔軟性がある。すなわち、アーキタイプは可変的であり、それはあるLEGOの指令が同じ基本要素に対していくつものオプションを許容するのと同様である。数学的に見れば、アーキタイプはF-Logicでの照会と同等である。アーキタイプの応用範囲という観点から見れば、アーキタイプは汎用的で再利用性が高く、合成可能 composable である。通常の場合、アーキタイプは実行時にテンプレートから利用されることで、データの取得や検証を行なう。
Archetypes are themselves instances of an archetype model, which defines a language in which to write archetypes; the syntax equivalent of the model is the Archetype Definition Language, ADL. These formalisms are specified in the openEHR Archetype Object Model (AOM) and ADL documents respectively. Each archetype is a set of constraints on the reference model, defining a subset of instances that are considered to conform to the subject of the archetype, e.g. "laboratory result". An archetype can thus be thought of as being similar to a LEGO� instruction sheet (e.g. for a tractor) that defines the configuration of LEGO� bricks making up a tractor. Archetypes are flexible; one archetype includes many variations, in the same way that a LEGO� instruction might include a number of options for the same basic object. Mathematically, an archetype is equivalent to a query in F-logic [5]. In terms of scope, archetypes are general-purpose, re-usable, and composable. For data capture and validation purposes, they are usually used at runtime by templates.
openEHRのテンプレートは、1個以上のアーキタイプを木構造として定義する。その際にひとつひとつのアーキタイプは、Composition, Section, Entry subtypesなどの様々な参照モデルのインスタンスに対して制約をほどこす。したがって、「生化学の結果」というObservationアーキタイプとか「SOAPの表題」というSectionアーキタイプなどのアーキタイプがあるが、テンプレートはこうしたアーキタイプを電子カルテ上にて「退院サマリー」とか「出産前検診」などという構造にまとめあげる。通常の場合、テンプレートは画面のフォームや印刷されたレポートに密接に関係するものであり、一般的にはメッセージの内容を決めるためにアプリケーションレベルにおいて情報の集まりを取得したり送信したりする。テンプレートは個別に開発されて利用されることが多いが、アーキタイプは(訳注:アプリケーションに限定されずに)幅広く利用される。
An openEHR Template is a specification that defines a tree of of one or more archetypes, each constraining instances of various reference model types, such as Composition, Section, Entry subtypes and so on. Thus, while there are likely to be archetypes for such things as "biochemistry results" (an Observation archetype) and "SOAP headings" (a Section archetype), templates are used to put archetypes together to form whole Compositions in the EHR, e.g. for "discharge summary", "antenatal exam" and so on. Templates usually correspond closely to screen forms, printed reports, and in general, complete application-level lumps of information to be captured or sent; they may therefore be used to define message content. They are generally developed and used locally, while archetypes are usually widely used.
テンプレートは実行時において既定値のデータ構造を生成し、入力データを検証する。それによって全ての電子カルデのデータがテンプレートによって参照されるアーキタイプに適合していることを保証する。とりわけ、それは語彙のみならずアーキタイプのパス構造を検証する。どのアーキタイプがデータ生成時に用いられたかはデータに書きこまれている。その形式は、対応するルートノードのアーキタイプ識別子とアーキタイプノード識別子 ([atnnnn]という形式のコードである)である。それらは規範的なノード名として振る舞い、かつパスの基本要素となる。同一のデータを修正する場合には、これらのアーキタイプノード識別子はアプリケーションが元のアーキタイプを取得することを可能とする。それによってデータの修正は元々の制約を保持することになる。
A template is used at runtime to create default data structures and to validate data input, ensuring that all data in the EHR conform to the constraints defined in the archetypes referenced by the template. In particular, it conforms to the path structure of the archetypes, as well as their terminological constraints. Which archetypes were used at data creation time is written into the data, in the form of both archetype identifiers at the relevant root nodes, and archetype node identifiers (the [atnnnn] codes), which act as normative node names, and which are in turn the basis for paths. When it comes time to modify the same data, these archetype node identifiers enable applications to retrieve and use the original archetypes, ensuring modifications respect the original constraints.
アーキタイプは意味論的な照会 semantic querying のための基盤をも提供する。照会はアーキタイプから抽出され、SELECT/FROM/WHEREで構成されたSQL文とW3C策定のXPathを融合させた言語でこれを行なう。
Archetypes also form the basis of semantic querying. Queries are expressed in a language which is a synthesis of SQL (SELECT/FROM/WHERE) and W3C XPaths, extracted from the archetypes.
10.2 アーキタイプの形式論とモデル
10.2 Archetype Formalisms and Models
概要
10.2.1 Overview
openEHRではアーキタイプはアーキタイプ・オブジェクト・モデル Archetype Object Model (AOM) によって定式化される。これはアーキタイプの意味をオブジェクト・モデルとして表現したものである。アーキタイプがメモリー上で展開されるとき(例えば、kernelと呼ばれるアーキタイプが組込まれた電子カルテシステム上など)、アーキタイプはこのモデルを表現したクラスのインスタンスとして存在する。このように、AOMはアーキタイプの意味を定義したコマンド文 statement である。
In openEHR, archetypes are formalised by the Archetype Object Model (AOM). This is an object model of the semantics of archetypes. When an archetype is represented in memory (for example in an archetype-enabled EHR "kernel"), the archetype will exist as instances of the classes of this model. The AOM is thus the definitive statement of the semantics of archetypes.
アーキタイプは様々な方法でシリアライズされる。openEHRにおける抽象的かつ標準的なシリアライズの方法は、アーキタイプ定義言語 (ADL) である。この言語はフレーム論理(F-logicとも呼ばれる)にもとづいた抽象的な言語であり、言語には専門用語 terminology が組込まれている。ADLアーキタイプはどんなアーキタイプの意味をも100%完全に表現できることが保証されており、AOMを構文として表現できるように設計されている。それにもかかわらず、場合によってはシリアライズの過程で情報が失なわれる可能性は否定できないし、現に情報の喪失は部分的に生じている。現実的な理由から、場合によってはXMLにもとづくシリアライズが利用されるであろう。シリアライズは将来的には dADLと呼ばれる文法によって完全に表現されるであろう。これはADLのオブジェクトをシリアライズする言語である。人間が視認するための画面描画にはHTML、RTF、その他のフォーマットが利用されることになる。
In serialised form, archetypes can be represented in various ways. The normative, abstract serialisation in openEHR is Archetype Definition Language (ADL). This is an abstract language based on Frame Logic queries (also known as F-logic [5]) with the addition of terminology. An ADL archetype is a guaranteed 100% lossless rendering of the semantics of any archetype, and is designed to be a syntactic analogue of the AOM. Nevertheless, other lossless and lossy serialisations are possible and some already exist. For practical purposes, XML-based serialisations are used in some situations. A serialisation purely expressed in dADL, the ADL object serialisation syntax will be available in the future. Various HTML, RTF and other formats are used for screen rendering and human review.
openEHRのテンプレートは dADLの文書として表現される。そのオブジェクト・モデルはテンプレート・オブジェクト・モデル (TOM) に適合することになる。
openEHR Templates are represented as dADL documents whose object model conforms to the Template Object Model (TOM).
10.2.2 アーキタイプ間の時間関係性
10.2.2 Design-time Relationships between Archetypes
アーキタイプはオブジェクトの構造を形式的に制約し、かつそれは拡張可能である。オブジェクト・モデルのクラスとして当然のごとく、それらは特化 specialised できるし、集合体として構成可能 composed である。特化したアーキタイプはモデル化を必要とする内容がすでに利用可能なアーキタイプが存在する時点で生成されるが、それはあまりに汎用的で具体性に欠いている。例えば、openEHR-EHR-OBSERVATION.laboratory.v1(訳注: http://www.oceaninformatics.biz/archetypes/ADL/entry/observation/openEHR-EHR-OBSERVATION.laboratory.v1.adl )というアーキタイプは「検体」をはじめとして「診断のためのサービス」「ともかく何かのタイプの一つの結果」「グループ化された検査結果」などという漠然とした概念を保持している。このアーキタイプはほとんどどんな臨床検査の結果をも表現することになる。しかしながら、openEHR-EHR-OBSERVATION.laboratory-glucose.v1(訳注: http://www.oceaninformatics.biz/archetypes/ADL/entry/observation/openEHR-EHR-OBSERVATION.laboratory-glucose.v1.adl )へと特化することは非常に有益であるし、あらかじめ容易に定義可能である。すなわち、こうした場合では単一の結果が「血糖値」として再定義されることになる。特化のための形式的なルールは以下のようになる。
- 特化したアーキタイプは、親となるアーキタイプに対してさらなる制約を付加するか、あるいは新たな制約を加えることである。
Archetypes are extensible formal constraint definitions of object structures. In common with object model classes, they can be specialised, as well as composed (i.e. aggregated). Specialised archetypes are created when an archetype is already available for the content that needs to be modelled, but it lacks detail or is too general. For example, the archetype openEHR-EHR-OBSERVATION.laboratory.v1 contains generic concepts of specimen', diagnostic service', a single result of any type, and a two-level result battery for grouped results. This archetype could be (and has been) used to represent nearly any kind of laboratory result data. However, specialisations such as openEHR-EHR-OBSERVATION.laboratory-glucose.v1 are extremely useful, and can be easily defined based on the predecessor; in this case, the single result node is redefined to be `blood glucose'. The formal rule for specialisation is that:
- a specialised archetype can only further narrow existing constraints in the parent (but it may add its own).
この効果として、特化したアーキタイプによって生成されたデータは親アーキタイプを基盤としたクエリーに常にマッチする。換言すれば、臨床検査という観察項目 laboratory' Observations に対するクエリーは血糖値という観察項目glucose' Observations の情報を正しく取得することになる。この仕組みはオントロジーにおける包含関係という基本的な原理に合致する。この包含関係の原理は、BとAが意味論的にIS-A関係に立つときにはBという型のインスタンスは同時にAという型のインスタンスでもあることを意味する。特化したアーキタイプは、親アーキタイプの識別子と下位要素の識別子を`-'でつなげた識別子によって表現される。
This has the effect that the data created with any specialised archetype will always be matched by queries based on the parent archetype - in other words, a query for laboratory' Observations will correctly retrieve glucose' Observations as well. This accords with the basic ontological principle of subsumption, which says that instances of a type B are also instances of type A, where type B is related to type A by the semantic relationship IS-A'. Specialised archetypes are indicated by the use of an identifier derived from the parent archetype, with a new sub-element of the semantic part of the identifier, separated by a -' character.
アーキタイプ間の関係には合成 composition もある。合成という関係をもとに小規模のアーキタイプを階層的に再利用して巨大なデータ構造を柔軟に制約することが可能となる。合成関係はアーキタイプ内のスロット slot によって定義される。アーキタイプ構造においてスロットにオブジェクト型を指定するのではなく、allow_archetypeという特別の制約を課し、それによってスロットの型を他のアーキタイプに制約する。例えば、アーキタイプ openEHR-EHR-SECTION.vital_signs.v1(訳注: http://www.oceaninformatics.biz/archetypes/ADL/section/openEHR-EHR-SECTION.vital_signs.v1.adl ) はバイタルサインに関する表題を定義すると同時に、その属性値として表題の下位項目になる観察項目 Observations を定義している。しかしながら、それら属性値をスロットにそのまま埋め込むのではなく、その箇所に観察項目アーキタイプ Observation archetypes に対する制約として指定している。もっとも単純な制約はアーキタイプ識別子を正規表現で指定するものである。より複雑な制約には、 /some/path[at0005] のように他のアーキタイプのパスとして記述する方法がある。このようにスロットはその箇所における可能なアーキタイプあるいは除外すべきアーキタイプを指定するという連結点 `chaining point' として定義される。無論、ひとつのアーキタイプだけに限定することも可能である。テンプレートは具体的な場面のあるスロットにおいていずれのアーキタイプが許容されるかを選択するために利用される。
The second relationship possible between archetypes is composition, allowing large data structures to be flexibly constrained via the hierarchical re-use of smaller archetypes. Composition is defined in terms of slots' within an archetype. A slot is a point in an archetype structure where, instead of specifying an object type inline, a special allow_archetype constraint is used to specify other archetypes constraining that same type, that may be used at that point. For example, the archetype openEHR-EHR-SECTION.vital_signs.v1 defines a heading structure for headings to do with vital signs. It also defines as its items attribute value (i.e. what comes under the heading) a number of possible Observations; however, rather than defining these inline, it specifies an archetype slot in the form of constraints on Observation archetypes that are allowed at that point. The simplest kind of constraint is in terms of regular expressions on archetype identifiers. More complex constraints can be stated in terms of paths in other archetypes (for example exists(/some/path[at0005])). A slot thus defines a chaining point' in terms of possible archetypes allowed or excluded at that point; limiting this to a single archetype is of course possible. Templates are used to choose which particular archetypes allowed at a slot will actually be used in a given circumstance.
10.3 データに対するアーキタイプとテンプレートの関係
10.3 Relationship of Archetypes and Templates to Data
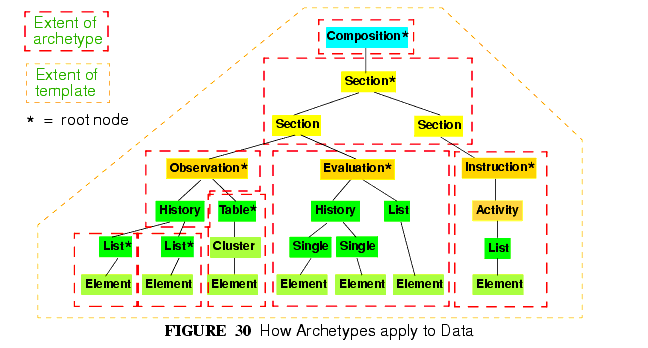
openEHRの参照モデルにおける上位レベルの構造内の全てのノードは、アーキタイプとして構成される archetypable ものである。これらの構造におけるある種のノードは根 root points としてのアーキタイプである。それぞれの上位レベルは常に根としてのアーキタイプであることを保証される。全ての上位レベル構造にただひとつのアーキタイプを用いることは理論的には可能であるが、多くの場合(特に COMPOSITION and PARTY)において、複数のアーキタイプが前述のスロット機構を用いて階層的に構成される。これによってアーキタイプのコンポーネント化と再利用が可能となる。上位レベル構造に階層的なアーキタイプが配置される場合、その構造の内部に根としてのアーキタイプが用いられる。例えば、COMPOSITIONの内部ではENTRYというインスタンス(すなわち、OBSERVATIONs, EVALUATIONなど)はほとんど常に根となる。SECTIONというインスタンスがSection構造の最上位のインスタンスであるならば、それは同時に根である。ディレクトリ構造におけるFOLDERというインスタンスも同じように根となる。他のノード(すなわち、SECTIONやITEM_STRUCTUREというインスタンス内部のノード)も根としてのアーキタイプとなるかも知れないが、これは実行時においてアーキタイプがどのようにデータに適用されるかに依存している。図30はアーキタイプとテンプレートがデータに対して適用される場面を表現している。
All nodes within the top-level information structures in the openEHR RM are "archetypable", with certain nodes within those structures being archetype "root points". Each top-level type is always guaranteed to be an archetype root point. Although it is theoretically possible to use a single archetype for an entire top-level structure, in most cases, particularly for COMPOSITION and PARTY, a hierarchical structure of multiple archetypes will be used, via the slot mechanism described above. This allows for componentisation and reusability of archetypes. When hierarchies of archetypes are used for a top-level structure, there will also be archetype root points in the interior of the structure. For example, within a COMPOSITION, ENTRY instances (i.e. OBSERVATIONs, EVALUATIONs etc.) are almost always root points. SECTION instances are root points if they are the top instance in a Section structure; similarly for FOLDER instances within a directory structure. Other nodes (e.g. interior SECTIONs, ITEM_STRUCTURE instances) might also be archetype root points, depending on how archetypes are applied at runtime to data. FIGURE 30 illustrates the application of archetypes and templates to data.

10.4 アーキタイプ利用可能な参照モデルデータ
10.4 Archetype-enabling of Reference Model Data
参照モデルのクラスは common.archetypedパッケージ (Common IM を参照)(訳注: http://www.openehr.org/uml/release-1.0.1/Browsable/_9_0_76d0249_1109005524093_410631_254Index.html )にあるLOCATABLEクラスを継承することで、アーキタイプの利用が有効となる。 LOCATABLEクラスは archetype_node_id と archetype_detailsの属性を持つ。データにおいて、前者(archetype_node_id属性)はアーキタイプの識別子を設定する。もしデータのノードが根 root pointならば、そのノードは生成するアーキタイプの識別子を複数格納し、archetype_details属性にはその根となるアーキタイプに適切な情報を保持するARCHETYPEDオブジェクトが設定される。もし、データのノードが根ノードでなければ、archetype_node_id属性はデータノードを生成するアーキタイプ内部ノード archetype interior node の識別子(atコードあるいはarchetype termコードと呼ばれる)を設定し、archetype_details属性は空となる。
Archetype-enabling of Reference Model classes is achieved via inheritance of the class LOCATABLE from the package common.archetyped (see Common IM). The LOCATABLE class includes the attributes archetype_node_id and archetype_details. In the data, the former carries an identifier from the archetype. If the node in the data is a root point, it carries the multipart identifier of the generating archetype, and archetype_details carries an ARCHETYPED object, containing information pertinent to archetype root points. If it is a non-root node, the archetype_node_id attribute carries the identifier (known as an "at", or "archetype term" code) of the archetype interior node that generated the data node, and the archetype_details attribute is void.
データ上の兄弟ノードが同一の archetype_node_id を保持することもありうる。なぜならば、アーキタイプはテンプレートそのものというよりはデータに対するパターンを提供するものだからである。換言すれば、アーキタイプのデザイン如何によっては、1個のアーキタイプがデータにおいて複製されることもある。
Sibling nodes in data can carry the same archetype_node_id in some cases, since archetypes provide a pattern for data, rather than an exact template. In other words, depending on the archetype design, a single archetype node may be replicated in the data.
このように openEHRのデータにおいては、インスタンスの構造に適合するようアーキタイプに特定の設定を定義しておき、それぞれの「アーキタイプによるデータ合成 archetyped data composition FootNote(一般的な名詞である composition を、openEHRと CEN EN 13606 で定義されている COMPOSITIONクラスと混同しないよう注意されたい。後者として特別に使う場合は、Composition と明記している。)」 がそのアーキタイプを実際に生成することになる。「生化学結果 biochemistry results」のためのアーキタイプはOBSERVATIONアーキタイプでもあり、OBSERVATIONオブジェクトが含むインスタンスの特定の構造を持つよう制約する。すなわち、"problem/SOAP headings"アーキタイプは、SECTIONオブジェクトがSOAPという表題を持った構造になるよう制約する。一般的に、「アーキタイプによるデータ合成」は 根ノードから末端ノードにいたるまでデータの合成を担当し、もし下位レベルの合成が定義されていれば、それぞれのレベルでデータが合成される。図30ではそれぞれのアーキタイプの領域が「アーキタイプによるデータ合成」を表わしている。
In this way, each archetyped data composition1 in openEHR data has a generating archetype which defines the particular configuration of instances to create the desired composition. An archetype for "biochemistry results" is an OBSERVATION archetype, and constrains the particular arrangement of instances beneath an OBSERVATION object; a "problem/SOAP headings" archetype constrains SECTION objects forming a SOAP headings structure. In general, an archetyped data composition is any composition of data starting at a root node and continuing to its leaf nodes, at which point lower-level compositions, if they exist, begin. Each of the archetyped areas and its subordinate archetyped areas in FIGURE 30 is an archetyped data composition.
電子カルテシステム(他のシステムでも)にてアーキタイプを利用してデータを生成することは、どんな上位レベルのオブジェクトにおいてもそのデータ構造がテンプレートから選択されたアーキタイプの合成によって定義された制約に適合していることが保証されることを意味している。その制約はオプションや値あるいは語彙に関する制約をも含むものである。
The result of the use of archetypes to create data in the EHR (and other systems) is that the structure of data in any top-level object conforms to the constraints defined in a composition of archetypes chosen by a template, including all optionality, value, and terminology constraints.
10.5 アーキタイプ、テンプーレートならびにパスについて
10.5 Archetypes, Templates and Paths
openEHRアーキテクチャのアーキタイプとテンプレートでは、パス式はいたるところで利用される。パスは図31で示されるように、Xpath互換の構文でアーキタイプとテンプレートから取り出され、属性の名称とアーキタイプのノードを構築する。
The use of openEHR archetypes and templates enables paths to be used ubiquitously in the openEHR architecture. Paths are extracted from Archetypes and templates, and are constructed from attribute names and archetype node identifiers, in an Xpath-compatible syntax, as shown in FIGURE 31.
パスは、例えば「拡張期血圧」というELEMENTノードのように、テンプレートやアーキタイプにおける任意のノードを識別するのに利用される。アーキタイプノードの識別子は実行時においてデータに組込まれるものであるから、アーキタイプのパスはそのアーキタイプの特定の部分に適合するデータのノードを抽出するのに利用され、これによって強力なクエリーが可能となる。パス式は、やはりXpathスタイルと同様に、データ中に格納されうる。openEHRのパスはページ63の「パスとロケータ」の箇所に詳しく述べられている。
These paths serve to identify any node in a template or archetype, such as the "diastolic blood pressure" ELEMENT node, deep within a "blood pressure measurement" archetype. Since archetype node identifiers are embedded into data at runtime, archetype paths can be used to extract data nodes conforming to particular parts of archetypes, providing a very powerful basis for querying. Paths can also be constructed into data, using more complex predicates (still in the Xpath style). Paths in openEHR are explained in detail under Paths and Locators on page 63.

10.6 実行時におけるアーキタイプとテンプレート
10.6 Archetypes and Templates at Runtime
10.6.1 概要
10.6.1 Overview
openEHRのアーキタイプとテンプレートは、実行時に計算機で処理可能であるように、形式的に設計されている。これらは主に2つの機能を実現する。ひとつは、データの取得やインポートの際にデータを検証する機能であり、これによってデータが参照モデルのみならずアーキタイプにも適合していることをが保証される。アーキタイプにもとづくデータの検証は、openEHRテンプレートを介する。ふたつめは、クエリーを構築するのための基盤となる機能である。データはアーキタイプをもとにして取得されるのであるから、全てのopenEHRのデータはテンプレート内部のアーキタイプの合成によって生成されれた意味的パス semantic paths に適合することが保証される。これらのパス(図31で示されるように)は、馴染あるSQLスタイル風の構文のなかに記述され、そうして形成されたクエリーによって意味論を加味したうえで必要な項目を取得できる。
openEHR archetypes and templates were designed as formal artefacts, so as to be computable at runtime. They perform two key functions. The first is to facilitate data validation at data capture or import time, i.e. to guarantee that data conform to not just the reference model, but also to the archetypes themselves. Data validation with archetypes is mediated by the use of openEHR Templates. The second function is as a design basis for queries. Since data are captured based on archetypes, all openEHR data are guaranteed to conform to the "semantic paths" that are created by the composition of archetypes within a template. The paths (such as those shown in FIGURE 31 above) are incorporated within a familiar SQL-style syntax, to form queries that can be evaluated to retrieve items on a semantic basis.
10.6.2 アーキタイプとテンプレートの配置
10.6.2 Deploying Archetypes and Templates
多くの場合においてアーキタイプは医療やその他の分野の専門家によってデザインされることになる。このため対象領域(例えば、産婦人科など)に関する十分な調査がしばしば必要とされる。開発プロセスは国家レベルあるいは国際レベルで実施されるかも知れず、相互チェック peer review や現実のシステムでの試験運用が必要となるだろう。これは、アーキタイプの持つ意味論的な重要性、すなわちモデルを再利用可能なものとすること、に合致する。結局のところ、アーキタイプがどのようなサイトに配置されるにせよ、アーキタイプは人々によく知られ品質が保証されたレポジトリに格納される可能性が高い。
Archetypes are mostly designed by clinical or other domain experts, and often require significant study of a subject area, for example, obstetrics. The development process may occur at a national or international level, and requires peer review and testing in real systems. This accords with the semantic value of archetypes, namely as reusable models of content. Consequently, from the point of view of any given site of deployment, archetypes are most likely to have been developed elsewhere, and to reside in a recognised, quality assured repository.
このようなレポジトリは何百いや何千ものアーキタイプを格納することになるかも知れない。しかしながら、多くの医療情報システムのサイトは比較的少ない数のアーキタイプのみを利用することだろう。医療の専門家は100個ほどのアーキタイプがあれば、主要なアーキタイプから数多く派生したアーキタイプを利用することで、通常業務ならびに急性期治療(臨床検査を含む)の80%はカバーできると予測している。しかしながら、いずれの100個のアーキタイプが必要となるかは、どのような種類の診療サービス(糖尿病専門の診療所、ガン病棟、病院の整形外科病棟、老人ホームなど)がそのサイトで提供されるかに依拠している。一般的には、ほとんど全てのサイトは公開されたアーキタイプのわずかな割合しか利用しないと予測される。なかには自分自身でアーキタイプを開発することもあるだろうか、この際には必ず既存のアーキタイプから特化させることになる。
Such a repository may contain hundreds or even thousands of archetypes. However, most EHR sites will only require a relatively small number. Clinical experts estimate that 100 archetypes would take care of 80% of routine general practice and acute care, including laboratory, with many of these being specialisations of a much smaller number of key archetypes. However, which 100 archetypes are useful for a given site may well vary based on the kind of health care provided, e.g. diabetic clinic, cancer, orthopedic hospital ward, aged care home. In general, it can be expected that nearly all archetype deployment sites will use only a small percentage of published archetypes. Some sites may also develop a small number of their own archetypes; invariably these will be specialisations of existing archetypes.
アーキタイプは、2段構造を持つopenEHRの第2層において、共有と品質保証を求めて注意深く設計される。その一方でテンプレートはよりローカルなものであり、テンプレートを介して多くのシステム設計者同士がアーキタイプと同意することになる。テンプレートは典型的には以下の3つの事項に基づいて設計されることになるだろう
- 画面やレポートをどのように設計するか
- どのアーキタイプがすでに利用可能であるか
- ローカル環境での語彙
テンプレートは、openEHRテンプレートオブジェクトモデル openEHR Template Object Model に適合するようにローカルな環境で生成される。
While archetypes constitute the main shared and carefully quality-assured design activity in the second layer of openEHR's two-level structure, templates are a more local affair, and are likely to be the point of contact of many system designers with archetypes. A template will typically be designed based on three things:
- what is desired to be in a screen form or report;
- what archetypes are already available;
- local usage of terminology.
Templates will generally be created locally by tools conforming to the openEHR Template Object Model.
GUIアプリケーションの場合は、処理の最後はGUIによる画面表示である。これは様々な方法と技術によって生成される。なかには画面が部分的あるいは完全にテンプレートをもとに生成されることもある。詳細は別として、画面フォームとテンプレートとの接続はツール環境で構築されることだろう。その結果、画面フォームがユーザの求めに応じて生成されたとき適切なテンプレートが活性化され、同時に適切なアーキタイプを活性化することになる。
In the case of GUI applications, the final step in the chain is GUI screen forms. These are created in a multitude of ways and technologies. In some cases, they will be partially or completely generated from templates. Regardless of the details, the connection between a screen form and a template will be established in the tooling environment, so that when the form is requested by a user, the relevant template will be activated, in turn activating the relevant archetypes.
より技術的な詳細は、多くのシステムを配置する際に重要となる。必要となるアーキタイプとテンプレートは事前にわかっているから、共有可能なopenEHRフォーム(すなわち、ADLやTOMのファイル)をレポジトリやローカルなツールから受けとり、それらを実行時に近いかたちでコンパイルすることになるだろう。通常、画面フォームはサイトごとに異なり、(コンパイルされた)アーキタイプとテンプートは実行効率を向上させ、検証されたアーキタイプとテンプレートのみがアプリケーションから実際に利用されることを保証する。こうしたシステムでは実行時のテンプレートは対応するアーキタイプのコピーのように振舞うことになる。
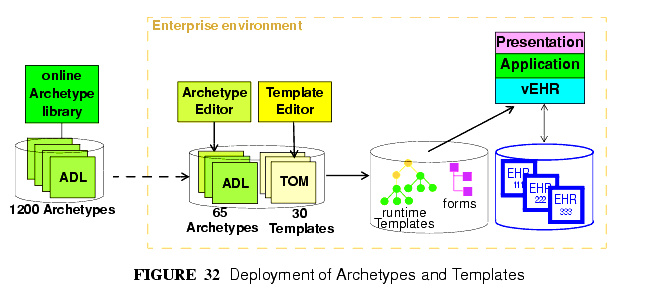
アーキタイプ、テンプレート、画面フォームが配置される様子は図32に記されている。
A further technical detail may come into play in many deployment situations: since the archetypes and templates required by the environment will be known in advance, they may well be compiled into a near-runtime form from the sharable openEHR form (i.e. ADL, TOM files) in which they are received from a repository or local tool. This form will usually differ from site to site, and both improves performance and ensures that only validated archetypes and templates will actually be accessed by applications. In such systems, runtime form of templates is most likely to incorporate copies of the relevant archetypes.
The deployment of archetypes, templates, and screen forms is shown in FIGURE 32.

10.6.3 データ取得時の検証
10.6.3 Validation during Data Capture
検証は、実行時におけるアーキタイプの主要な機能である。そもそもアーキタイプ指向のデータは検証機能にしたがって生成され、変更される。アーキタイプ指向の検証は、GUIアプリケーションもしくはデータ受信のサービスで利用される。元となるデータ(キーボード入力、受信したXML、あるいはその他のメッセージ)はさまざまであるが、論理的なプロセスは同じである。すなわち、入力ストリームにしたがってアーキタイプ指向のopenEHRデータが生成されることになる。
Validation is the primary runtime function of archetypes - it is how "archetype-based" data are created in the first place, and modified thereafter. Archetype-based validation can be used in a GUI application or in a data import service. Although the source of the data (keystrokes or received XML or other messages) is different, the logical process is the same: create archetype-based openEHR data according to the input stream.
実行時のプロセスはケアを提供するサービスの実装や設定によってその詳細が異なるかもしれないが、その主要な目的は同じであろう。特定のサイトにおけるアーキタイプは、常にそのサイトやシステム向けに開発されたテンプレートから利用される。すなわち、テンプレートは画面フォームや他の形式的な生成物 formal artefacts と連動し、それらを介してユーザあるいはアプリケーションとアーキタイプが接続される。ユーザが画面上に作成されたアーキタイプを選択するのに応じて、テンプレートの一部は実行時に生成されるのが通常である。ユーザは意識することはないだろうがそれにもかかわらず、適切なアーキタイプに応じてデータが生成され検証されるまでには、対応するテンプレートは完全に特定されてなければならない。
The process at runtime may vary in some details according to implementations and other aspects of the care setting, but the main thrust will be the same. The archetypes used at a particular site will always be mediated at runtime by openEHR templates developed for that site or system; these will usually be linked to screen forms or other formal artefacts that enable the connection between archetypes and the user or application. It will not be uncommon for a template to be constructed partially at runtime, due to user choices of archetypes being made on the screen, although of course the user will not be directly aware of this. Regardless, by the time data are created and validated against the relevant archetypes, the template that does the job will be completely specified.
実際にデータが生成されたり格納されるプロセスは図33に図示されている。プロセスの本質はkernelコンポーネントにあり、ここにおいてテンプレート空間 template space とデータ空間 data space が維持されることでデータの生成と検証の作業が実行される。テンプレート空間は表示された画面フォームから取得されたテンプレートとアーキタイプを格納している。データ空間は、画面に対するユーザの振舞いに応じて生成されたデータ構造(openEHR参照モデルのインスタンス)を格納している。最終的にデータが格納されるタイミングでデータはテンプレートとアーキタイプの定義に適合していることが保証される。このチェックはユーザがデータ構造に変更を加えるたびに実行される。格納された全てのデータはそのノードがアーキタイプノード識別子の形式に依拠しており、そうした意味でデータノードはアーキタイプの意味論的な刻印 semantic imprint である。データモデルにおけるこうした包含関係によって、アーキタイプによって生成された全てのデータがアーキタイプパスを用いて照会可能となることが保証される。XMLによる表現では、アーキタイプノード識別子はXMLの属性(タグ内部に配置されるということ)として表現され、これによってXPathがこれらの識別子をもとにしたデータを簡便に探索することができる(次章で詳細を述べる)。
The actual process of data creation and committal is illustrated in FIGURE 33. The essence of the process is that a "kernel" component performs the task of data creation and validation by maintaining a "template space" and a "data space". The former contains the template and archetypes retrieved due to a screen form being displayed; the latter contains the data structures (instances of the openEHR reference model) that are constructed due to user activity on the screen. When data are finally committed, they are guaranteed to conform to the template/archetype definitions, due to the checks that are made each time the user tries to change the data structure. The committed data contain a "semantic imprint" of the generating archetypes, in the form of archetype node identifiers on every node of the data. This simple inclusion in the data model ensures that all archetypes data are queryable by the use of archetype paths. In XML representations, the archetype node ids are represented as XML attributes (i.e. inside the tag), thus enabling XPaths to be conveniently navigated through the data based on these identifiers (more details on this are in the next section).

もしもデータがあとで変更された場合、データは対応するテンプレートならびにアーキタイプとともにkernelコンポーネントに渡される。そして、データに組込まれているノード識別子によって、kernelコンポーネントはデータの変更に応じて適切な検証を実行することになる。
If data are later modified, they are brought into the kernel along with the relevant template and archetypes, and the embedded node identifiers allow the kernel to continue to perform appropriate checking of changes to the data.
10.6.4 照会
10.6.4 Querying
アーキタイプが持つもう一つの機能は、照会をサポートすることである。前述と次章に書かれているとおり、アーキタイプから抽出されたパスはデータに対する照会の基礎となる。照会はAQL(Archetype Query Language)で定義されている。その構文はSQLとアーキタイプから抽出されたXPathスタイルを融合されたものである。以下に「BMI値が30 kg/m2以上の患者のBMI値を求めよ」という内容を意味するAQLの例を記しておく。
The second major computational function of archetypes is to support querying. As described above, and in the next section, the paths extracted from archetypes are the basis for queries into the data. Queries are defined in AQL (Archetype Query Language), which is essentially a synthesis of SQL and XPath style paths extracted from archetypes. The following is an example AQL query meaning "Get the BMI values which are more than 30 kg/m2 for a specific patient":
SELECT o/[at0000]/data[at0001]/events[at0002]/data[at0003]/item[0004]/value FROM EHR [uid=@ehrUid]
CONTAINS COMPOSITION c [openEHR-EHR-COMPOSITION.report.v1]
CONTAINS OBSERVATION o[openEHR-EHR-OBSERVATION.body_mass_index.v1]
WHERE o/[at0000]/data[at0001]/events[at0002]/data[at0003]/item[0004]/value > 30
10.7 openEHRアーキタイプ
10.7 The openEHR Archteypes
十分にレビューされたアーキタイプの一群は、openEHRのWebサイトである http://svn.openehr.org/knowledge/archetypes/dev/index.html から利用可能である。このコレクションは常時追加されており、国際的に利用可能なもののみならずそれぞれの国々に特有のアーキライプも含まれている。
A set of heavily reviewed archetypes is available on the openEHR website at http://svn.openehr.org/knowledge/archetypes/dev/index.html. This collection is being added to all the time, and includes archetypes developed for specific countries or other "realms" as well as globally applicable ones.
1Note: care must be taken not to confuse the general term "composition" with the specific use of this word in openEHR and CEN EN 13606, defined by the COMPOSITION class; the specific use is always indicated by using the term "Composition".
Attachments (4)
- archetypinga.gif (45.4 KB ) - added by 17 years ago.
- archetypingb.gif (98.0 KB ) - added by 17 years ago.
- archetyping4.gif (41.0 KB ) - added by 17 years ago.
- archetyping3.gif (78.1 KB ) - added by 17 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip